| Aufwand | in h | h/Woche | Punkte |
|---|---|---|---|
| Besuch der Vorlesung | 21 | 1.5 | 0.7 |
| Vor und Nachbereitung | 21 | 1.5 | 0.7 |
| Lesen der Texte | 42 | 3.0 | 1.4 |
| Übungsaufgaben in R | 50 | 3.6 | 1.7 |
| Prüfungsvorbereitung | 42 | 3.0 | 1.4 |
| Studienteilnahmepunkte | 4 | 0.3 | 0.1 |
| Summe für 6 ECTS * 30h | 180 | 12.9 | 6.0 |
Statistik und Datenanalyse: Aufbau
Mittelwert, Standardabweichung, Korrelation
Zusatzliteratur (Wiederholung Statistik Einführung)
Für die Wiederholung von «Statistik: Einführung».

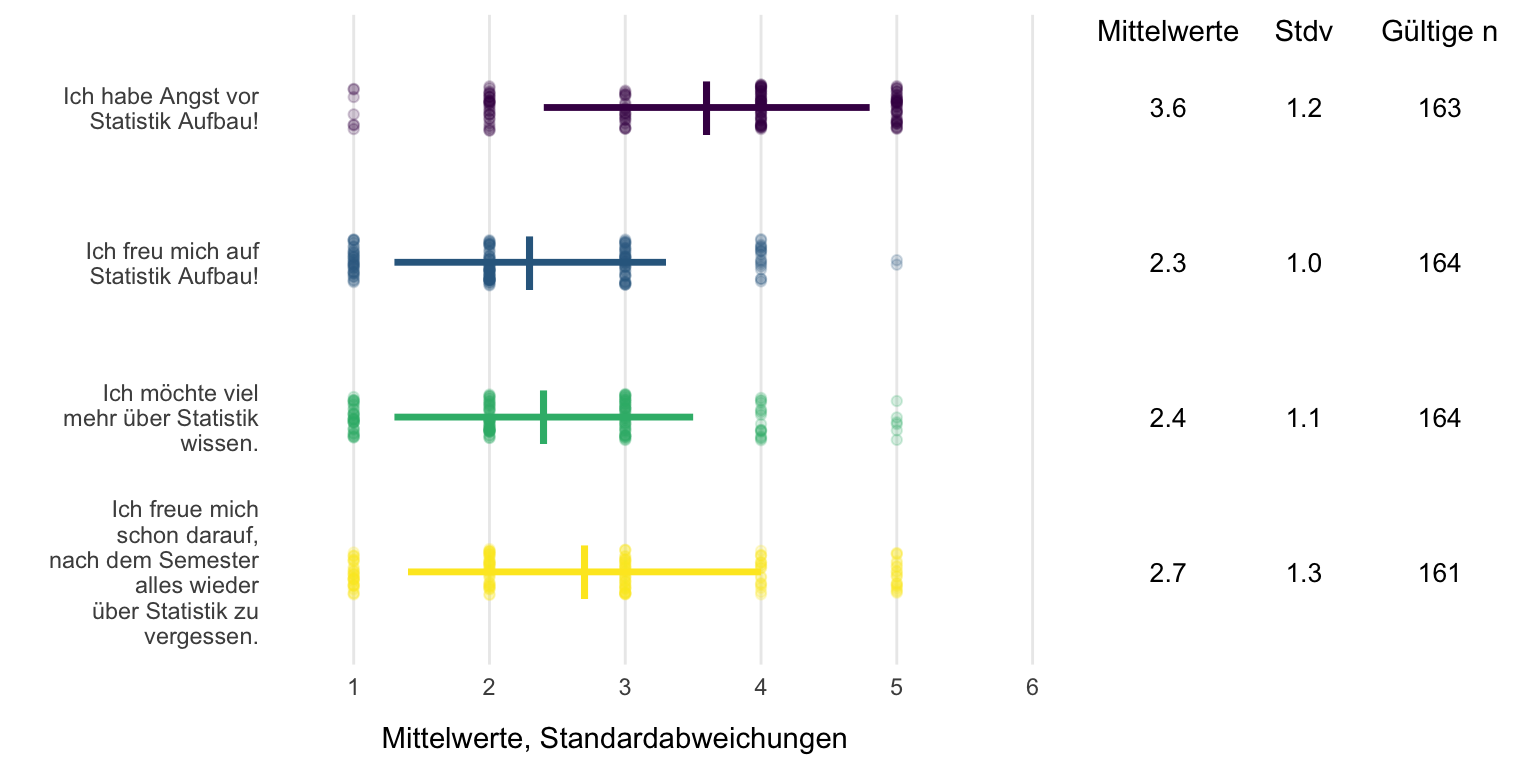
Erwartungen
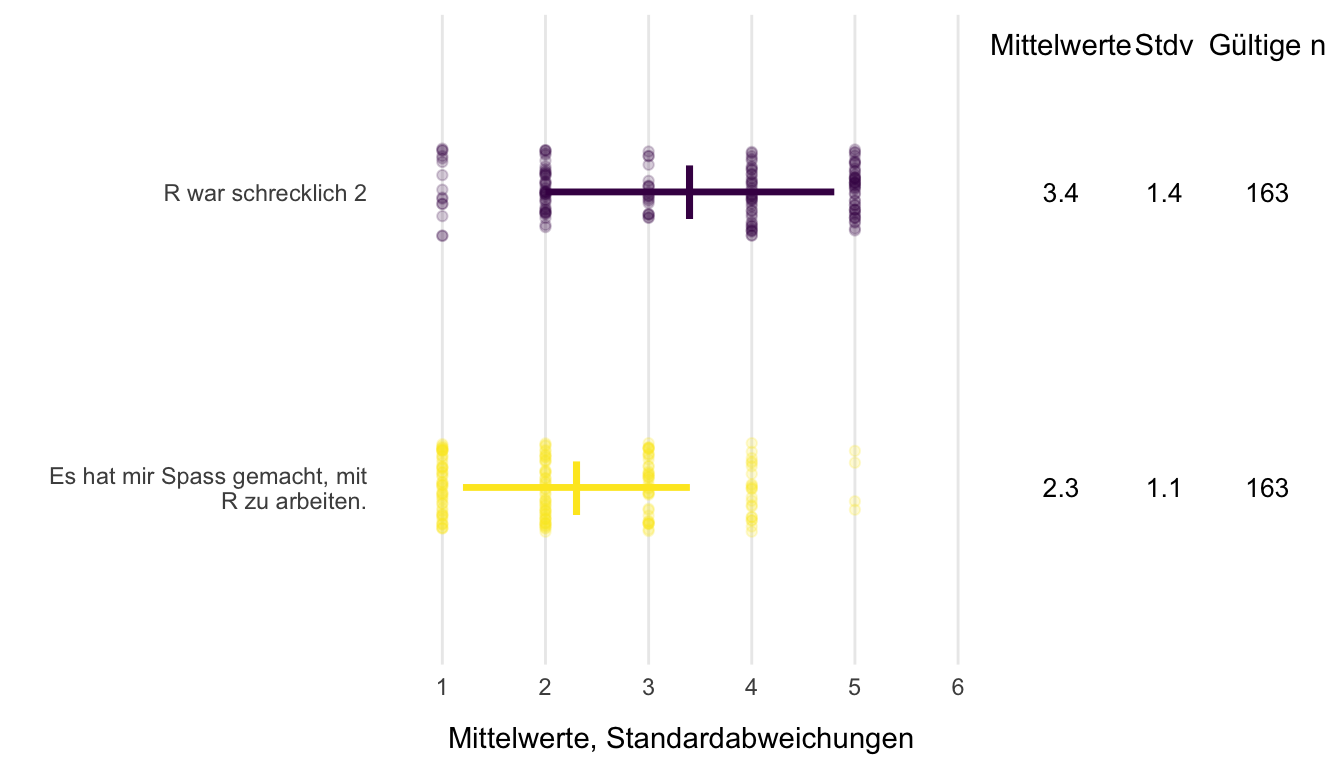
Umgang mit R
Ziele

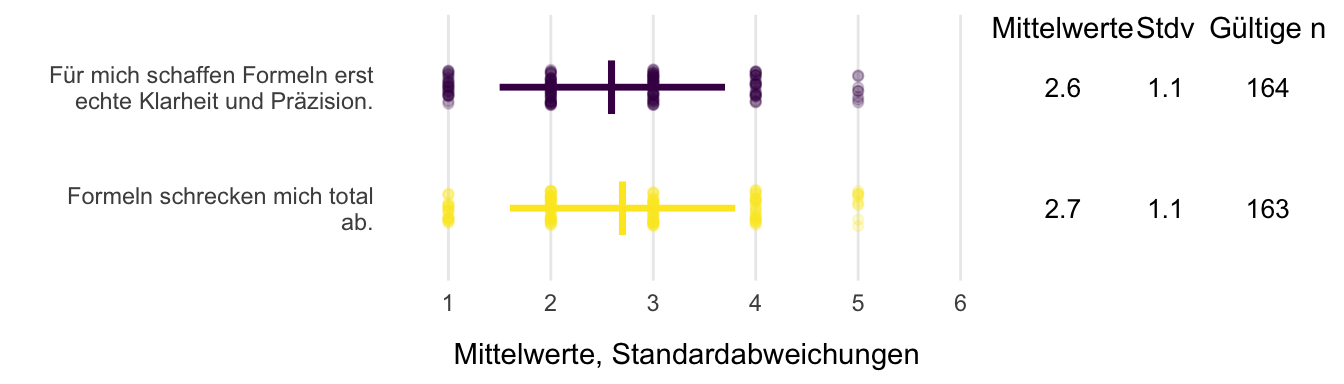
Was geht mit Formeln?
Spass und Freude
R-Code anzeigen
DATEN |>
haven::zap_formats() |>
select(E201_02, E201_06) |>
filter(E201_02 >= 0 & E201_06 >= 0) |> # sjmisc::frq()
# sjlabelled::label_to_colnames() |>
ggplot(aes(x = E201_06, y = E201_02)) +
geom_jitter(width = 0, height = 0) +
labs(x = "Es hat mir Spass gemacht, mit R zu arbeiten", y = "Ich freu mich auf Statistik Aufbau")+
geom_smooth(method=lm) +
theme_minimal()
Statistik war leicht
R-Code anzeigen
DATEN |>
haven::zap_formats() |>
select(E201_02, E201_06) |> # sjmisc::frq()
filter(E201_02 >= 0 & E201_06 >= 0) |>
sjlabelled::remove_all_labels() |>
ggplot(aes(x = E201_06, y = E201_02, colour = E201_06)) +
geom_jitter(width = 0.2, height = .2) +
scale_color_viridis() +
labs(x = "Es hat mir Spass gemacht, mit R zu arbeiten.", y = "Ich freu mich auf Statistik Aufbau!")+
geom_smooth(method=lm) +
ggpubr::stat_cor(method = "pearson", label.x = 4, label.y = 1.3, p.digits = 3, p.accuracy = .05) +
theme_minimal() +
theme(legend.position = "none")
Statistik war leicht (doppelt)
R-Code anzeigen
DATEN |>
haven::zap_formats() |>
select(E102_01, E201_03) |> # sjmisc::frq()
filter(E102_01 >= 0 & E201_03 >= 0) |>
sjlabelled::remove_all_labels() |>
ggplot(aes(x = E102_01, y = E201_03, colour = E102_01)) +
geom_jitter(width = 0.2, height = 0.2) +
scale_color_viridis() +
labs(x = "Statistik war leicht", y = "Statistik war leicht 2")+
geom_smooth(method=lm) +
ggpubr::stat_cor(method = "pearson", label.x = 4, label.y = 1.3, p.digits = 3, p.accuracy = .05) +
theme_minimal() +
theme(legend.position = "none")
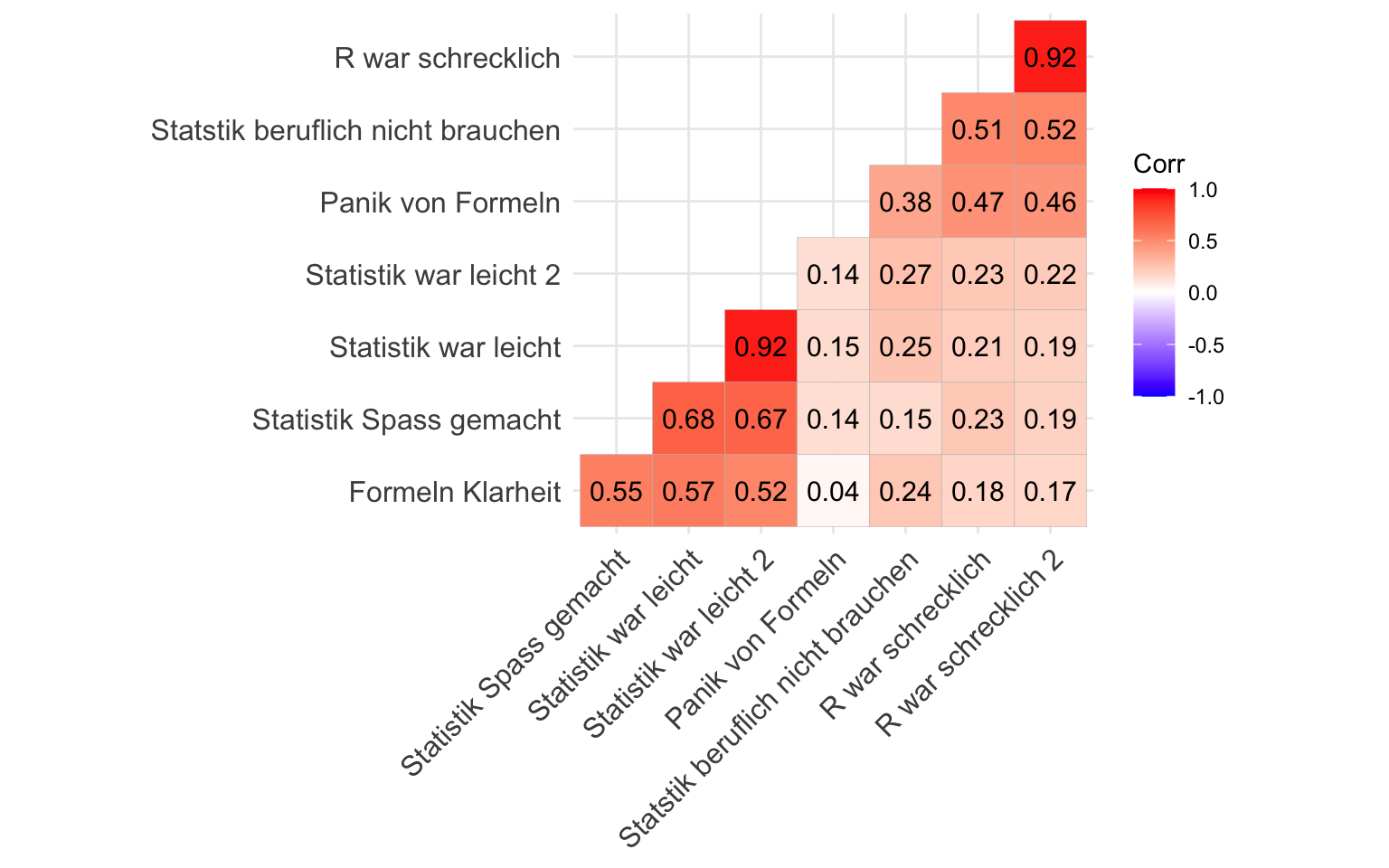
Korrelationen
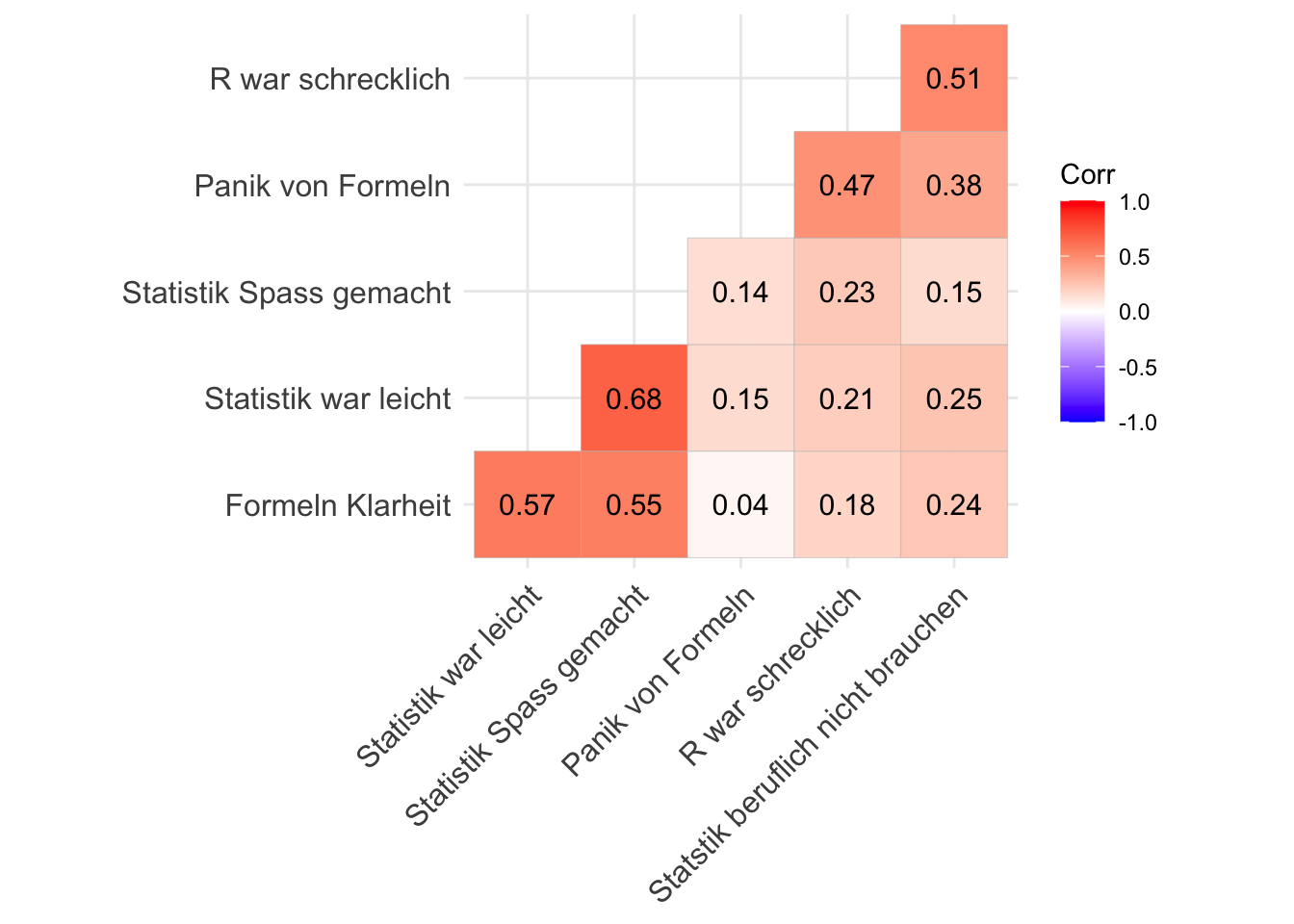
Korrelation doppelte Frage
Ausblick
