Zum Termin bitte durchgehen: Übung 4 und Text Zerback Wirz! lesen! (liegt beides auch in OLAT unter Materialien bzw. Texte)
11.1 Die Folien zur Sitzung
Der Vorlesungsmitschnitt
Übung 4
In der Übung beschäftigen wir uns mit Daten des Untergangs der Titanic. Schauen Sie sich jeweils die Befehle an und finden Sie heraus, was die Befehle machen. Machen Sie sich Notizen, wenn Sie etwas nicht verstehen.
Daten einlesen
Legen Sie für diese Übung einen Ordner an, erstellen Sie dort eine qmd und kopieren Sie die Folgenden Daten in einen dortigen Unterordner «data»:
Suchen und nehmen Sie den Datensatz «train.csv»: Downlaod der Daten: https://www.kaggle.com/competitions/titanic/data
Code
# DATEN_titanic <- read_csv("data/titanic/train.csv") # lese beim ersten Mal die Daten einDATEN_titanic <-readRDS("data/titanic/train.RDS") # Lese nach dem ersten Mal so die Daten ein.saveRDS(DATEN_titanic, "data/titanic/train.RDS") # speichere die Daten
11.2 Datenaufbereitung
Code
DATEN_titanic <- DATEN_titanic |>mutate(Kinder = Age <14) |># Kinder werden als unter 14 Jährige definiertmutate(Age_z = Age -mean(Age, na.rm =TRUE)) |># Das alter um den Mittelwert verschieben (zentrieren)mutate(Pclass_f =factor(Pclass, levels =c(3, 2, 1)), Cabin_D =ifelse(is.na(Cabin), 0, 1))
… und mal die Daten angucken:
Code
DATEN_titanic |># mache eine Zusammenfassung der Datensummary() ## PassengerId Survived Pclass Name Sex ## Min. : 1.0 Min. :0.0000 Min. :1.000 Length:891 Length:891 ## 1st Qu.:223.5 1st Qu.:0.0000 1st Qu.:2.000 Class :character Class :character ## Median :446.0 Median :0.0000 Median :3.000 Mode :character Mode :character ## Mean :446.0 Mean :0.3838 Mean :2.309 ## 3rd Qu.:668.5 3rd Qu.:1.0000 3rd Qu.:3.000 ## Max. :891.0 Max. :1.0000 Max. :3.000 ## ## Age SibSp Parch Ticket Fare ## Min. : 0.42 Min. :0.000 Min. :0.0000 Length:891 Min. : 0.00 ## 1st Qu.:20.12 1st Qu.:0.000 1st Qu.:0.0000 Class :character 1st Qu.: 7.91 ## Median :28.00 Median :0.000 Median :0.0000 Mode :character Median : 14.45 ## Mean :29.70 Mean :0.523 Mean :0.3816 Mean : 32.20 ## 3rd Qu.:38.00 3rd Qu.:1.000 3rd Qu.:0.0000 3rd Qu.: 31.00 ## Max. :80.00 Max. :8.000 Max. :6.0000 Max. :512.33 ## NA's :177 ## Cabin Embarked Kinder Age_z Pclass_f Cabin_D ## Length:891 S :644 Mode :logical Min. :-29.279 3:491 Min. :0.000 ## Class :character C :168 FALSE:643 1st Qu.: -9.574 2:184 1st Qu.:0.000 ## Mode :character Q : 77 TRUE :71 Median : -1.699 1:216 Median :0.000 ## NA's: 2 NA's :177 Mean : 0.000 Mean :0.229 ## 3rd Qu.: 8.301 3rd Qu.:0.000 ## Max. : 50.301 Max. :1.000 ## NA's :177
Die PassengerId ist einefach eine Identifikationsnummer.
Es gibt dann eine Variable, die «Survived» heisst, die ein Minimum von 0 hat und ein Maximum von 1. Das deutet sehr auf eine Dummy hin. Da der Durchschnitt («Mean») = 0.38 ist, wissen wir jetzt schon, dass 38 Prozent der Passagiere überlebt haben (der Mittelwert einer Dummy ist immer der Prozentsatz der 1er-Gruppe).
Dann kommt noch der Name als Zeichenvariable,
das Alter, das von 0.42 bis 80 geht. Von 177 Personen fehlen die Altersangaben.
Informieren Sie sich über die übrigen Variablen auf (https://www.kaggle.com/competitions/titanic/data)[«Kaggle»].
Daten in Trainings- und Testdaten aufteilen
Was passiert hier?
Code
# Setze eine Zufallszahl, damit die Ergebnisse replizierbar sind, also nicht jedes Mal eine neue Zufallszahl gesetzt wird und die Ergebnisse (bisschen) abweichenset.seed(12345)# Ziehe eine Zufallsstichprobe aus dem Filmdatensatz und bezeichne ihn als "train", also Trainingsdatensatz, mit dem die "Maschine" trainiert wirdtrain <- DATEN_titanic |>sample_frac(.75)# Bilde aus dem Rest der nicht für "train" gezogenen Fälle einen Test-Datensatz, indem nach 'id' die Fälle aus "Filme" das Gegenteil (anti) von zusammengetan (join) werden.test <-anti_join(DATEN_titanic, train, by ='PassengerId')
Sehen kann man nach diesem r-Chunk übrigens nichts, weil nur Datensätze im Hintergrund aufgeteilt wurden. Also suchen wir mal nach guten Datenvisualisierungen.
Übung: Experimentieren Sie mit verschiedenen Zahlen in set.seed() und grösseren und kleineren Werten in sample_frac().
Datenvisualisierung
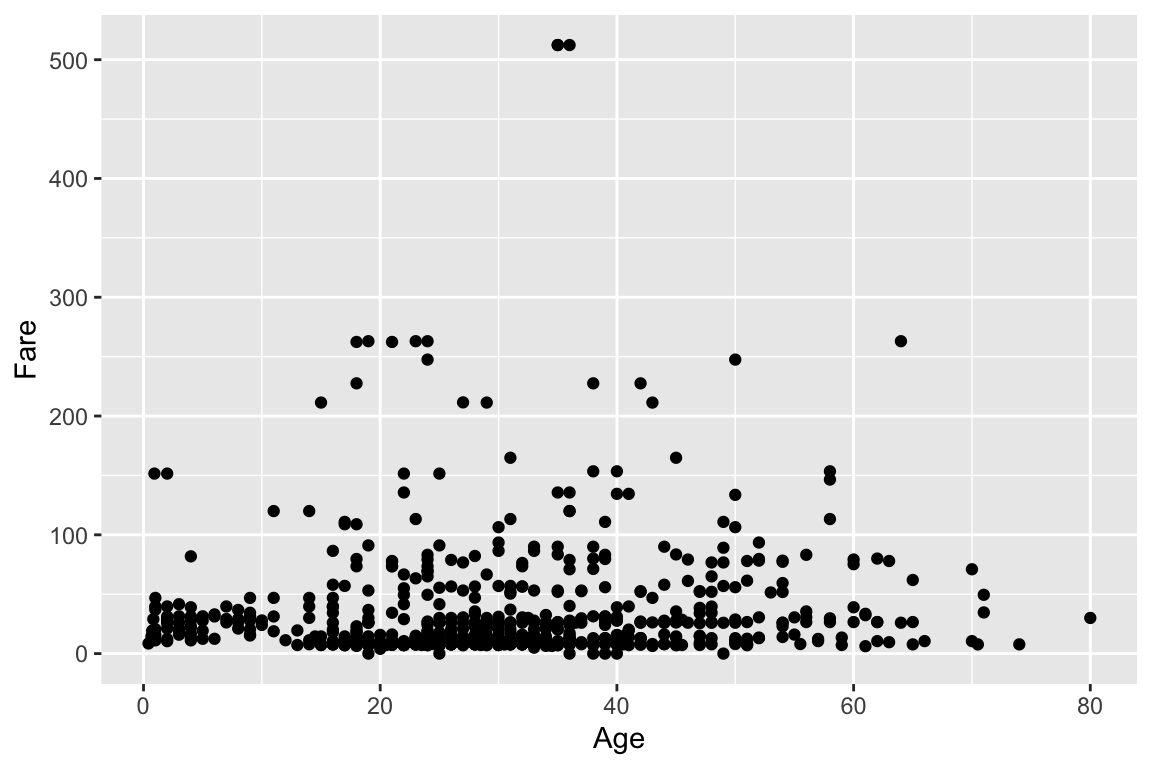
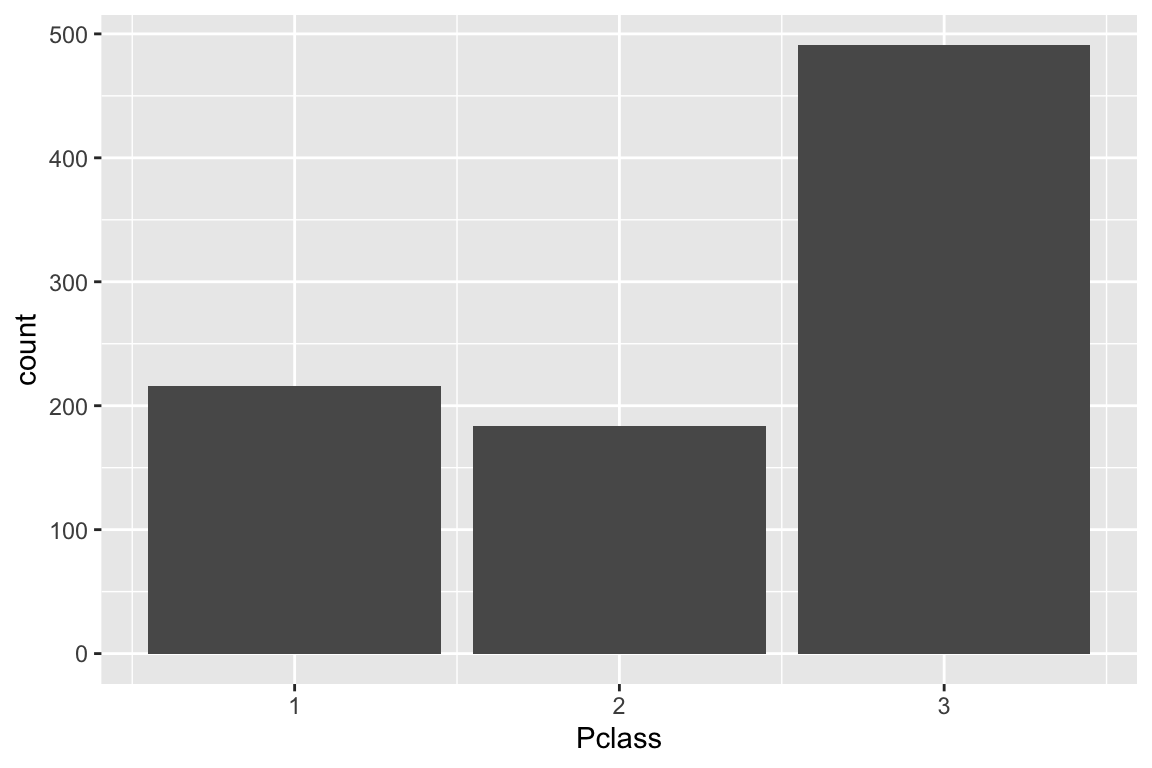
Eine einfache Darstellungsmöglichkeit ist ein sogenannter «Scatterplot» der die Lage von Fällen in ein Koordinatensystem einteilt, das durch zwei Variablen gebildet wird. Im Beispiel (Abbildung @ref(titanic-Datenvisualisierungen)) ist es das Alter der Passagiere «Age» und der Fahrpreis «Fare». Als Zweites haben wir ein Balkendiagramm für die Passagierklassen. Im letzten sehr aufwendigen Plotgrafik werden die Zweierbeziehungen aller Variablen dargestellt, also wie sie miteinander korrelieren (obere Nebendiagonalen), wie ihre Verteilung ist (auf der Diagonale mit Namen) und wie ihre gemeinsame Streuung ist, also ein Scatterplot in der unteren Nebendiagonalen. Mehr zu diesen SPLOM finden Sie hier: https://cran.r-project.org/web/packages/psych/vignettes/intro.pdf.
R-Code
# Erstelle einen Scatterplot (Punktewolke)DATEN_titanic |>ggplot(aes(x = Age, y = Fare)) +geom_point() ## Warning: Removed 177 rows containing missing values (`geom_point()`).# Erstelle ein BalkendiagrammDATEN_titanic |>ggplot(aes(x=Pclass)) +geom_bar()# Alle auf einmalpsych::pairs.panels(DATEN_titanic) ## Warning in cor(x, y, use = "pairwise", method = method): the standard deviation is zero## Warning in cor(x, y, use = "pairwise", method = method): the standard deviation is zero
Modellbildung für den Fahrpreis
Übung: Experimentieren Sie mit dem Syntax! Kopieren Sie sich die Zeile für das Modell, löschen von «Age_z» bis «Kinder» alles heraus und schätzen Sie mal. Schauen Sie sich das Ergebnis gut an und achten Sie darauf, was passiert, wenn Sie die Summanden für I(Age_z^2) usw. wieder in das Modell tun. Am Ende können Sie versuchen das Modell durch weitere Variablen ergänzen und verbessern oder andere Teile wieder herausnehmen. Manche Variablen wurden erst noch erstellt (zB «Kinder» oder «Age_z»). Die entsprechende Datenaufbereitung.qmd können Sie hier abrufen .
Übung: Interpretieren Sie den Output!
Code
fit_titanic <-lm(log(Fare +1) ~ Sex + Age_z +I(Age_z^2) + Survived + Pclass_f + Kinder, data = train)broom::tidy(fit_titanic) |>mutate(across(where(is.numeric), ~round(.,3)))|> gt::gt()
term
estimate
std.error
statistic
p.value
(Intercept)
2.657
0.076
35.047
0.000
Sexmale
-0.316
0.070
-4.520
0.000
Age_z
-0.003
0.003
-1.009
0.314
I(Age_z^2)
0.000
0.000
-0.406
0.685
Survived
-0.077
0.073
-1.050
0.294
Pclass_f2
0.492
0.072
6.859
0.000
Pclass_f1
1.778
0.077
23.104
0.000
KinderTRUE
0.607
0.173
3.515
0.000
Code
broom::glance(fit_titanic)|>round(2)|> gt::gt()
r.squared
adj.r.squared
sigma
statistic
p.value
df
logLik
AIC
BIC
deviance
df.residual
nobs
0.58
0.57
0.64
103.29
0
7
-517.85
1053.7
1092.26
216.7
528
536
Regressionsoutput mit sjPlot::tab_model
Code
sjPlot::tab_model(fit_titanic,show.std =TRUE, # zeige die standardisierten Koeffizientenshow.est =TRUE, # zeige die unstandardisierten estimatesshow.r2 =TRUE, # zeige R^2show.fstat =FALSE, # zeige die F-Statistikstring.est ="b", # beschrifte die Estimator mit bstring.std ="std. b"# beschrifte die standardisierten b mit std. b )## Formula contains log- or sqrt-terms.## See help("standardize") for how such terms are standardized.
log(Fare+1)
Predictors
b
std. b
CI
standardized CI
p
std. p
(Intercept)
2.66
0.83
2.51 – 2.81
0.80 – 0.87
<0.001
<0.001
Sex [male]
-0.32
-0.06
-0.45 – -0.18
-0.10 – -0.02
<0.001
0.003
Age z
-0.00
-0.02
-0.01 – 0.00
-0.05 – 0.00
0.314
0.063
Age z^2
-0.00
-0.00
-0.00 – 0.00
-0.02 – 0.01
0.685
0.639
Survived
-0.08
-0.00
-0.22 – 0.07
-0.02 – 0.02
0.294
0.914
Pclass f [2]
0.49
0.06
0.35 – 0.63
0.02 – 0.10
<0.001
0.004
Pclass f [1]
1.78
0.44
1.63 – 1.93
0.39 – 0.48
<0.001
<0.001
KinderTRUE
0.61
0.05
0.27 – 0.95
-0.04 – 0.15
<0.001
0.272
Observations
536
R2 / R2 adjusted
0.578 / 0.572
Als auch nicht ganz schlechte Alternative kann gtsummary::tbl_regression benutzt werden, was durch weitere gepipte Befehle angepasst und ergänzt werden kann.
Regressionsoutput mit gtsummary::tbl_regression
Übung: Was für ein Problem sehen Sie im folgenden Output? Bei welcher Befehlszeile müssten Sie das # wegnehmen, um das Problem zu lösen?
Code
## Alternative zum sjPlot-Ouptut. Sie können entscheiden, was Sie besser finden. fit_titanic |> gtsummary::tbl_regression() |> gtsummary::add_vif() |># gtsummary::add_global_p() |> # Gebe die Signifikanzen je Variable raus (Varianzaufklärung)# gtsummary::modify_header(estimate = "**b**") |> # Sorgt dafür, dass die b's nicht Beta heissen, sondern b gtsummary::add_glance_source_note()
Übung: Suchen Sie die Befehle und führen Sie sie aus:
Die möglichen Verletzungen der Voraussetzungen sind:
Multikollinearität
Deutliche Abweichung von der Normalverteilung in den Fehlern
Heteroskedastizität
Outlier
Algorithmus für den Fahrpreis
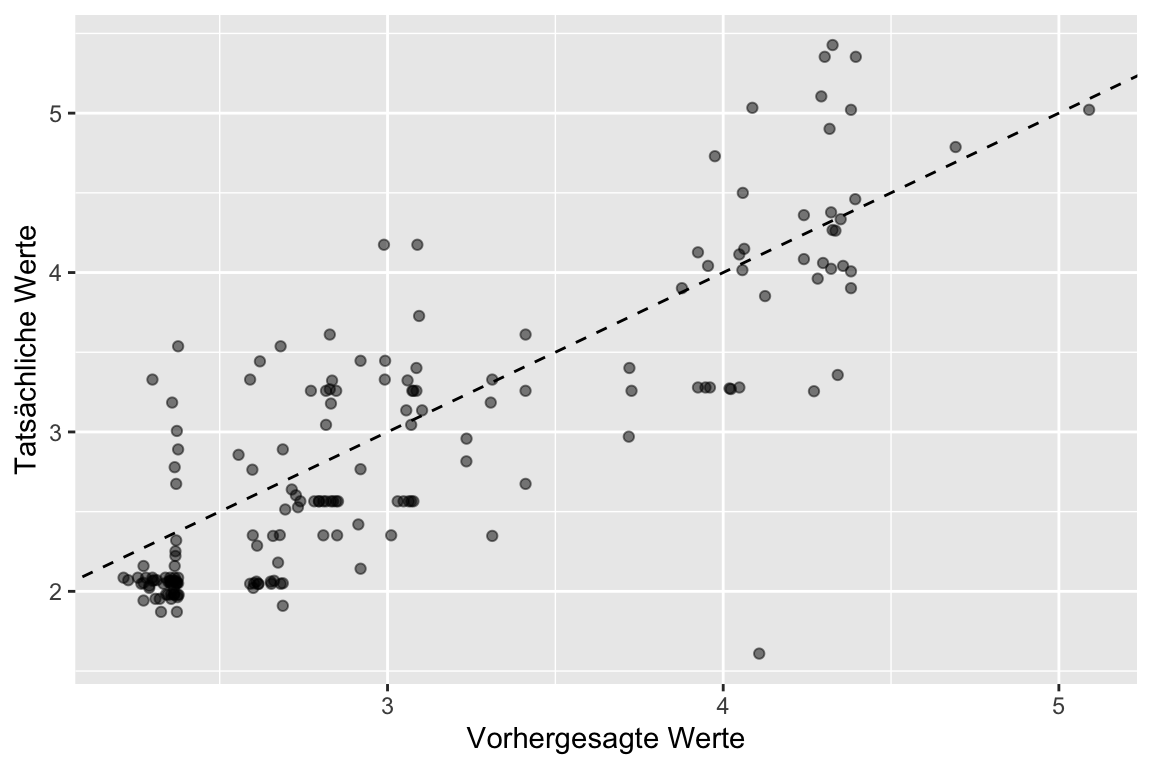
Prognosewerte erstellen:
Code
preds <-predict(fit_titanic, test) modelEval <-cbind(log(test$Fare), preds) |>as_tibble() ## Warning: The `x` argument of `as_tibble.matrix()` must have unique column names if `.name_repair`## is omitted as of tibble 2.0.0.## ℹ Using compatibility `.name_repair`.# Beschrifte die Spaltencolnames(modelEval) <-c('actual', 'predicted')plot <-ggplot(modelEval, aes(x = predicted, y = actual)) +# Create a diagonal line:geom_abline(lty =2) +geom_point(alpha =0.5) +labs(y ="Tatsächliche Werte", x ="Vorhergesagte Werte") plot## Warning: Removed 45 rows containing missing values (`geom_point()`).
Überlebensprognose
Zweite Analyse: Überlebensprognose (Dummy) mit linearer Regression. Was denken Sie?
Code
DATEN_titanic <-readRDS("data/titanic/train.RDS")model1 <-lm(Survived ~ Pclass_f + Sex + Age_z +I(Age_z^2) + Kinder, data=train)broom::tidy(model1) |>mutate(p.value = scales::pvalue(p.value)) |># damit der p-Wert nicht mit endlosen Nullen dargestellt wirdmutate(across(where(is.numeric), ~round(.x, 3))) |># über alle numerischen Variablen hinweg, runde sie auf 3 Stellen gt::gt()
term
estimate
std.error
statistic
p.value
(Intercept)
0.579
0.038
15.427
<0.001
Pclass_f2
0.180
0.042
4.285
<0.001
Pclass_f1
0.376
0.043
8.772
<0.001
Sexmale
-0.508
0.035
-14.392
<0.001
Age_z
-0.003
0.002
-1.464
0.144
I(Age_z^2)
0.000
0.000
-0.184
0.854
KinderTRUE
0.125
0.103
1.217
0.224
Code
broom::glance(model1)|>mutate(p.value = scales::pvalue(p.value)) |># damit der p-Wert nicht mit endlosen Nullen dargestellt wirdmutate(across(where(is.numeric), ~round(.x, 3))) |># über alle numerischen Variablen hinweg, runde sie auf 3 Stellen gt::gt()
r.squared
adj.r.squared
sigma
statistic
p.value
df
logLik
AIC
BIC
deviance
df.residual
nobs
0.403
0.397
0.382
59.587
<0.001
6
-241.157
498.314
532.587
77.177
529
536
Logistische Regression
Code
model2 <-glm(Survived ~ Pclass_f + Sex + Kinder, family=binomial, data=train)# Berechnung der Odds-Ratios (OR) für Pclass_f2 und Pclass_f1 um sie unten im Text verwenden zu könnenOR_Pclass_f2 <-round(exp(summary(model2)$coefficients["Pclass_f2", 1]), 2) OR_Pclass_f1 <-round(exp(summary(model2)$coefficients["Pclass_f1", 1]), 2)broom::tidy(model2)|>mutate(p.value = scales::pvalue(p.value)) |># damit der p-Wert nicht mit endlosen Nullen dargestellt wirdmutate(across(where(is.numeric), ~round(.x, 3))) |># über alle numerischen Variablen hinweg, runde sie auf 3 Stellen gt::gt()
term
estimate
std.error
statistic
p.value
(Intercept)
0.235
0.221
1.065
0.287
Pclass_f2
1.130
0.286
3.946
<0.001
Pclass_f1
2.158
0.287
7.518
<0.001
Sexmale
-2.703
0.244
-11.087
<0.001
KinderTRUE
1.173
0.373
3.142
0.002
Code
broom::glance(model2)|>mutate(across(where(is.numeric), ~round(.x, 3))) |># damit der p-Wert nicht mit endlosen Nullen dargestellt wird gt::gt()
null.deviance
df.null
logLik
AIC
BIC
deviance
df.residual
nobs
724.287
535
-241.935
493.871
515.291
483.871
531
536
Kennwerte
Übung: Interpretieren Sie den Output
Code
model2 <-glm(Survived ~ Pclass_f + Sex + Kinder, family=binomial, data=train)sjPlot::tab_model(model2,title ="Überlebensanalyse zum Titanicunglück mit sjPlot",show.est =TRUE, # zeige die estimatesshow.r2 =TRUE, # zeige R^2show.fstat =TRUE# zeige die F-Statistik )
Überlebensanalyse zum Titanicunglück mit sjPlot
Survived
Predictors
Odds Ratios
CI
p
(Intercept)
1.27
0.82 – 1.96
0.287
Pclass f [2]
3.10
1.77 – 5.47
<0.001
Pclass f [1]
8.65
4.99 – 15.41
<0.001
Sex [male]
0.07
0.04 – 0.11
<0.001
KinderTRUE
3.23
1.56 – 6.78
0.002
Observations
536
R2 Tjur
0.404
Wieder auch mit gtsummary::
Code
model2 |> gtsummary::tbl_regression(exponentiate =TRUE) |> gtsummary::add_vif() |># gtsummary::add_global_p() |> # damit könnte man die Signifikanz ganzer Faktoren testen, statt jede Ausprägung gegen die Referenz gtsummary::add_glance_source_note() |> gtsummary::modify_caption("**Überlebensanalyse zum Titanicunglück mit gtsummary**")
Überlebensanalyse zum Titanicunglück mit gtsummary