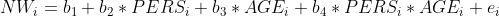Unter dem Video (Kommentarbereich) finden Sie ein Inhaltsverzeichnis, mit dem Sie schneller die LEF finden, zu denen Sie sich die Besprechung nochmal anschauen möchten. Wenn Sie Fragen haben, dann gerne wieder im Forum.
Fehler: Bei Essayaufgabe 5.6 behaupt ich, dass das \(b_2\) den Anstieg der beiden parallelen Geraden festlegt (im Video 55:15). Das ist aber falsch, wenn das \(b_2\) zur Dummyvariablen gehören soll. Dann ist es nämlich der Mittelwertunterschied zwischen den beiden Gruppen, die durch die Dummy bestimmt werden (0-Gruppe und 1-Gruppe). Was ich erzählt habe, stimmt, wenn das \(b_2\) zur metrischen gehört.
Sie bekommen an der Klausur die Formelsammlung als ein Blatt Papier mit allen relevanten Formeln auf einer Seite:
Die Formelsammlung
LEF 1
Essayfragen
Was ist der Unterschied zwischen unstandardisierten und standardisierten Kennwerten?
Welche Masse der zentralen Tendenz kennen Sie?
Welche Streumasse kennen Sie?
Was kommt raus, wenn man die Covarianz einer Variablen mit sich selbst berechnet?
Welche Skalenniveaus kennen Sie?
Was macht eine Nominalskala aus?
Was macht eine metrische Skala aus?
MC-Fragen
MC 1.1.
MC 1.1: Sind folgende Aussagen richtig oder falsch?
MC_1_1 = [ ["Der Mittelwert ist dasselbe wie der Durchschnitt.","richtig"], ["Der Mittelwert einer dichotomen Variablen entspricht dem Prozentsatz der 1-Werte.","richtig"], ['Der Mittelwert wird auch als "Mittel" oder "Arithmetisches Mittel" bezeichnet.',"richtig"], ["Je grösser ein Mittelwert ist, desto eher ist er signifikant.","falsch"]]viewof answers_1_1 =quizInput({questions: MC_1_1,options: ["richtig","falsch"]})Punkte_1_1 = {const Sum = (answers_1_1[0] == MC_1_1[0][1])*1+ (answers_1_1[1] == MC_1_1[1][1])*1+ (answers_1_1[2] == MC_1_1[2][1])*1+ (answers_1_1[3] == MC_1_1[3][1])*1var Punkte_1_1 = Sum -2if (Punkte_1_1 <1) {Punkte_1_1 =0}return(Punkte_1_1)}
Punkte:
MC 1.2.
MC 1.2: Sind folgende Aussagen richtig oder falsch?
MC_1_2 = [ ["Die Standardabweichung ist die standardisierte Form der Varianz.","falsch"], ["Die Standardabweichung hat n-1 Freiheitsgrade.","richtig"], ['Die Standardabweichung "s" liegt immer zwischen 0 und 1.',"falsch"], ["Die Standardabweichung ist die durchschnittliche Abweichung vom Mittelwert.","falsch"]]viewof answers_1_2 =quizInput({questions: MC_1_2,options: ["richtig","falsch"]})Punkte_1_2 = {const Sum = (answers_1_2[0] == MC_1_2[0][1])*1+ (answers_1_2[1] == MC_1_2[1][1])*1+ (answers_1_2[2] == MC_1_2[2][1])*1+ (answers_1_2[3] == MC_1_2[3][1])*1var Punkte_1_2 = Sum -2if (Punkte_1_2 <1) {Punkte_1_2 =0}return(Punkte_1_2)}
Punkte:
MC 1.3.
MC 1.3: Sind folgende Aussagen richtig oder falsch?
MC_1_3 = [ ["Die Covarianz ist das Quadrat der Korrelation.","falsch"], ["Die Covarianz ist skalenabhängig und kann daher negativ oder positiv und unendlich klein oder gross sein.","richtig"], ['Die Korrelation "r" liegt immer zwischen 0 und 1.',"falsch"], ["Eine Korrelation von genau 0 kann nie signifikant sein.","richtig"]]viewof answers_1_3 =quizInput({questions: MC_1_3,options: ["richtig","falsch"]})Punkte_1_3 = {const Sum = (answers_1_3[0] == MC_1_3[0][1])*1+ (answers_1_3[1] == MC_1_3[1][1])*1+ (answers_1_3[2] == MC_1_3[2][1])*1+ (answers_1_3[3] == MC_1_3[3][1])*1var Punkte_1_3 = Sum -2if (Punkte_1_3 <1) {Punkte_1_3 =0}return(Punkte_1_3)}
Punkte:
MC 1.4.
MC 1.4: Sind folgende Aussagen richtig oder falsch?
MC_1_4 = [ ["Bei der bivariaten Korrelation sind r und die Wurzel aus R² identisch.","richtig"], ["Das b einer bivariaten Regressionsgeraden liegt immer zwischen -1 und 1.","falsch"], ['Wenn das b nicht signifikant ist, kann nicht mit 95% Wahrscheinlichkeit ausgeschlossen werden, dass es in Wirklichkeit Null ist oder ein zum Stichprobenwert entgegengesetztes Vorzeichen hat.',"richtig"], ["Wenn ein b signifikant ist, dann ist auch BETA signifikant.","richtig"]]viewof answers_1_4 =quizInput({questions: MC_1_4,options: ["richtig","falsch"]})Punkte_1_4 = {const Sum = (answers_1_4[0] == MC_1_4[0][1])*1+ (answers_1_4[1] == MC_1_4[1][1])*1+ (answers_1_4[2] == MC_1_4[2][1])*1+ (answers_1_4[3] == MC_1_4[3][1])*1var Punkte_1_4 = Sum -2if (Punkte_1_4 <1) {Punkte_1_4 =0}return(Punkte_1_4)}
Punkte:
MC 1.5.
MC 1.5: Sind folgende Aussagen richtig oder falsch?
MC_1_5 = [ ["Statistische Signifikanz bedeutet im Grunde wissenschaftliche Relevanz.","falsch"], ["Bei kleinen Stichproben können Ergebnisse auch schon mal signifikant werden, obwohl die Effekte so kleine sind, dass sie zu vernachlässigen sind.","falsch"], ['Je grösser n, desto schneller wird derselbe Effekt (z.B. Mittelwertunterschied) signifikant.',"richtig"], ["Wenn man einmal ein Signifkanzniveau (z.B. 95%) festgelegt hat, sollte man auch dabei bleiben.","richtig"]]viewof answers_1_5 =quizInput({questions: MC_1_5,options: ["richtig","falsch"]})Punkte_1_5 = {const Sum = (answers_1_5[0] == MC_1_5[0][1])*1+ (answers_1_5[1] == MC_1_5[1][1])*1+ (answers_1_5[2] == MC_1_5[2][1])*1+ (answers_1_5[3] == MC_1_5[3][1])*1var Punkte_1_5 = Sum -2if (Punkte_1_5 <1) {Punkte_1_5 =0}return(Punkte_1_5)}
Punkte:
MC 1.6.
MC 1.6: Sind folgende Aussagen richtig oder falsch?
MC_1_6 = [ ["Wenn das Konfidenzintervall eines Kennwertes kleiner als .05 ist, dann ist es signifikant.","falsch"], ["Wenn das Konfidenzintervall eines Mittelwertes die 0 nicht einschliesst, dann ist der Mittelwert signifikant von 0 verschieden.","richtig"], ['Wählt man ein höheres Signifikanzniveau (z.B. 99% statt 95%), dann wird das Konfidenzintervall breiter.',"richtig"], ["Je breiter ein Konfidenzintervall, desto besser ist ein Kennwert interpretierbar.","falsch"]]viewof answers_1_6 =quizInput({questions: MC_1_6,options: ["richtig","falsch"]})Punkte_1_6 = {const Sum = (answers_1_6[0] == MC_1_6[0][1])*1+ (answers_1_6[1] == MC_1_6[1][1])*1+ (answers_1_6[2] == MC_1_6[2][1])*1+ (answers_1_6[3] == MC_1_6[3][1])*1var Punkte_1_6 = Sum -2if (Punkte_1_6 <1) {Punkte_1_6 =0}return(Punkte_1_6)}
Für die MC der LEF 1: von Punkten, was % und etwa einer entspricht.
LEF 2
Essayfragen 2
E2.1 Wie ist die Korrelation definiert?
E2.2 Was ist das Analyseziel einer Regression?
E2.3 Wie sind die Regressionskoeffizienten gekennzeichnet? (Welcher Buchstabe)
E2.4 Was ist der Unterschied zwischen BETA und \(\beta\)?
E2.5 Was drückt der Standardfehler der Regressionskoeffizienten b aus?
E2.6 Mit welchen Kennwerten kann die Modellgüte insgesamt bewertet werden?
E2.7 Was ist a) \(R^2_{adj.}\) und b) wann würde man es verwenden?
E2.8 Was sagt die Signifikanz des F-Tests für ein Regressionsmodell aus?
MC-Fragen 2
MC 2.1.
MC 2.2: Sind folgende Aussagen richtig oder falsch?
MC_2_1 = [ ["Die Regressionskoeffizienten (b’s) sind unstandardisiert.","richtig"], ["Die standardisierten Regressionskoeffizienten messen die unbekannten Parameter β.","falsch"], ['Die standardisierten Regressionskoeffizienten sind wie Korrelationen interpretierbar.',"richtig"], ["Die Standardfehler der b’s sind immer 1.","falsch"]]viewof answers_2_1 =quizInput({questions: MC_2_1,options: ["richtig","falsch"]})Punkte_2_1 = {const Sum = (answers_2_1[0] == MC_2_1[0][1])*1+ (answers_2_1[1] == MC_2_1[1][1])*1+ (answers_2_1[2] == MC_2_1[2][1])*1+ (answers_2_1[3] == MC_2_1[3][1])*1var Punkte_2_1 = Sum -2if (Punkte_2_1 <1) {Punkte_2_1 =0}return(Punkte_2_1)}
Punkte:
MC 2.2.
MC 2.2: Sind folgende Aussagen richtig oder falsch?
MC_2_2 = [ ["Das Bestimmtheitsmass R² gibt an, welcher Varianzanteil der AV durch die UV bzw. die UVs erklärt werden kann.","richtig"], ["R²_adj. wird nur bei sehr grossen Stichproben gebraucht, um zufällige Signifikanzen zu vermeiden.","falsch"], ['Der F-Test zum R testet, ob alle UVs signifikant sind.',"falsch"], ["Wenn R² kleiner als .05 ist, dann ist die Regression signifikant.","falsch"]]viewof answers_2_2 =quizInput({questions: MC_2_2,options: ["richtig","falsch"]})Punkte_2_2 = {const Sum = (answers_2_2[0] == MC_2_2[0][1])*1+ (answers_2_2[1] == MC_2_2[1][1])*1+ (answers_2_2[2] == MC_2_2[2][1])*1+ (answers_2_2[3] == MC_2_2[3][1])*1var Punkte_2_2 = Sum -2if (Punkte_2_2 <1) {Punkte_2_2 =0}return(Punkte_2_2)}
Punkte:
MC 2.3.
MC 2.3: Sind folgende Aussagen richtig oder falsch?
MC_2_3 = [ ["Die standardisierten Regressionskoeffizienten entsprechen bei der bivariaten Regression der Korrelation.","richtig"], ["Die Regressionskoeffizienten b liegen immer zwischen -1 und 1.","falsch"], ['Das Bestimmtheitsmass R² gibt den Prozentanstieg der Regressionsgeraden an.',"falsch"], ["Die Konstante in der Regressionsgleichung wird bei multivariaten Modellen auch als b gekennzeichnet.","richtig"]]viewof answers_2_3 =quizInput({questions: MC_2_3,options: ["richtig","falsch"]})Punkte_2_3 = {const Sum = (answers_2_3[0] == MC_2_3[0][1])*1+ (answers_2_3[1] == MC_2_3[1][1])*1+ (answers_2_3[2] == MC_2_3[2][1])*1+ (answers_2_3[3] == MC_2_3[3][1])*1var Punkte_2_3 = Sum -2if (Punkte_2_3 <1) {Punkte_2_3 =0}return(Punkte_2_3)}
Punkte:
MC 2.4.
MC 2.4: Sind folgende Aussagen richtig oder falsch?
MC_2_4 = [ ["Bei der multivariaten Regression hängt b auch von der Covarianz der UVs ab","richtig"], ["Wenn es zwei UVs gibt, spricht man schon von «multivariat»","richtig"], ['Wenn ein b signifikant ist, wird auch R² des Gesamtmodells signifikant.',"richtig"], ["R² gibt an, wie viel Prozent der Varianz der AV durch alle UVs zusammen erklärt werden können.","richtig"]]viewof answers_2_4 =quizInput({questions: MC_2_4,options: ["richtig","falsch"]})Punkte_2_4 = {const Sum = (answers_2_4[0] == MC_2_4[0][1])*1+ (answers_2_4[1] == MC_2_4[1][1])*1+ (answers_2_4[2] == MC_2_4[2][1])*1+ (answers_2_4[3] == MC_2_4[3][1])*1var Punkte_2_4 = Sum -2if (Punkte_2_4 <1) {Punkte_2_4 =0}return(Punkte_2_4)}
Punkte:
MC 2.5.
MC 2.5: Sind folgende Aussagen richtig oder falsch?
MC_2_5 = [ ["R-Studio ist eine Programmiersprache für statistische Analysen.","falsch"], ["R ist eine Benutzer:innenoberfläche für die Programmiersprache R-Studio","falsch"], ['tidyverse ist eine Sammlung von R-Paketen.',"richtig"], ["Wenn man Drittvariablen «herausrechnet», werden die anderen b's immer kleiner.","falsch"]]viewof answers_2_5 =quizInput({questions: MC_2_5,options: ["richtig","falsch"]})Punkte_2_5 = {const Sum = (answers_2_5[0] == MC_2_5[0][1])*1+ (answers_2_5[1] == MC_2_5[1][1])*1+ (answers_2_5[2] == MC_2_5[2][1])*1+ (answers_2_5[3] == MC_2_5[3][1])*1var Punkte_2_5 = Sum -2if (Punkte_2_5 <1) {Punkte_2_5 =0}return(Punkte_2_5)}
Punkte:
MC 2.6.
MC 2.6: Sind folgende Aussagen richtig oder falsch?
MC_2_6 = [ ["Wenn man Drittvariablen «herausrechnet», werden die anderen b's immer kleiner.","falsch"], ["Für die standardisierten Regressionskoeffizienten können auch Konfidenzintervalle angegeben werden.","richtig"], ['Die Standardfehler von BETAS sind immer 1.',"falsch"], ["Regressionen sind eine Form der GLM.","richtig"]]viewof answers_2_6 =quizInput({questions: MC_2_6,options: ["richtig","falsch"]})Punkte_2_6 = {const Sum = (answers_2_6[0] == MC_2_6[0][1])*1+ (answers_2_6[1] == MC_2_6[1][1])*1+ (answers_2_6[2] == MC_2_6[2][1])*1+ (answers_2_6[3] == MC_2_6[3][1])*1var Punkte_2_6 = Sum -2if (Punkte_2_6 <1) {Punkte_2_6 =0}return(Punkte_2_6)}
Für LEF 2: von Punkten, was % und etwa einer entspricht.
LEF 3
Essayfragen 3
E3.1 Welches sind die Voraussetzungen für die Schätzung von Regressionen?
E3.2 Was bedeutet «Bias»?
E3.3 Was sagt Ihnen der Toleranzwert TOL?
E3.4 Was bedeutet Multikollinearität?
E3.5 Welche Kennwerte kennen Sie, mit denen Sie Multikollinearität abschätzen können?
E3.6 Wie reagieren a) p-Werte und b) Konfidenzintervalle auf Multikolliniearität?
E3.7 Warum kann man die volle Modellspezifikation nicht überprüfen?
E3.8 Was haben Theoriearbeit und Modellspezifikation miteinander zu tun?
E3.9 Was bedeutet es, dass die Variablen fix sein sollen?
MC-Fragen 3
MC 3.1.
MC 3.1: Sind folgende Aussagen richtig oder falsch?
MC_3_1 = [ ["Mit OLS werden die Voraussetzungen für Regressionen geprüft.","falsch"], ["Die Regressionskoeffizienten werden verzerrt geschätzt, wenn die Variablen nicht fix sind. ","richtig"], ["Bivariate Regressionen sind in der Regel unterspezifiziert.","richtig"], ["Die Suche nach der vollständigen Modellspezifikation macht wissenschaftlichen Fortschritt aus.","richtig"]]viewof answers_3_1 =quizInput({questions: MC_3_1,options: ["richtig","falsch"]})Punkte_3_1 = {const Sum = (answers_3_1[0] == MC_3_1[0][1])*1+ (answers_3_1[1] == MC_3_1[1][1])*1+ (answers_3_1[2] == MC_3_1[2][1])*1+ (answers_3_1[3] == MC_3_1[3][1])*1var Punkte_3_1 = Sum -2if (Punkte_3_1 <1) {Punkte_3_1 =0}return(Punkte_3_1)}
Punkte:
MC 3.2.
MC 3.2: Sind folgende Aussagen richtig oder falsch?
MC_3_2 = [ ["BLUE ist das Akronym für Beta Linear Unknown Error.","falsch"], ["Ist die Multikollinearität stark (TOL < .5) ist der Standardfehler des b inflationiert, der p-Wert grösser und das KI grösser. ","richtig"], ["Wenn die Multikollinearität perfekt ist, ist das Modell-R² = 1.","falsch"], ["Multikollinearität betrifft oft nur zwei Variablen gegenseitig.","richtig"]]viewof answers_3_2 =quizInput({questions: MC_3_2,options: ["richtig","falsch"]})Punkte_3_2 = {const Sum = (answers_3_2[0] == MC_3_2[0][1])*1+ (answers_3_2[1] == MC_3_2[1][1])*1+ (answers_3_2[2] == MC_3_2[2][1])*1+ (answers_3_2[3] == MC_3_2[3][1])*1var Punkte_3_2 = Sum -2if (Punkte_3_2 <1) {Punkte_3_2 =0}return(Punkte_3_2)}
Punkte:
MC 3.3.
MC 3.3: Sind folgende Aussagen richtig oder falsch?
MC_3_3 = [ ["Homoskedastitzität beschreibt die Anforderung, dass die Residuen normalverteilt sind.","falsch"], ["Heteroskedastizität lässt die Standardfehler der b's verzerrt schätzen.","richtig"], ["Homoskedastizität ist oft eine Folge nichtlinearer Zusammenhänge. ","falsch"], ["Nichtlineare Zusammenhänge können nicht mit linearen Modellen analysiert werden.","falsch"]]viewof answers_3_3 =quizInput({questions: MC_3_3,options: ["richtig","falsch"]})Punkte_3_3 = {const Sum = (answers_3_3[0] == MC_3_3[0][1])*1+ (answers_3_3[1] == MC_3_3[1][1])*1+ (answers_3_3[2] == MC_3_3[2][1])*1+ (answers_3_3[3] == MC_3_3[3][1])*1var Punkte_3_3 = Sum -2if (Punkte_3_3 <1) {Punkte_3_3 =0}return(Punkte_3_3)}
Punkte:
MC 3.4.
MC 3.4: Sind folgende Aussagen richtig oder falsch?
MC_3_4 = [ ["Jede UV muss normalverteilt sein, damit Regressionen gerechnet werden dürfen.","falsch"], ["Die abhängige Variable muss metrisch sein, um eine einfache Regression rechnen zu dürfen.","richtig"], ["Wenn die Residuen normalverteilt sind, dürfen keine Regressionen gerechnet werden. ","falsch"], ["Bei Querschnitterhebungen spielt die Anforderung untereinander unabhängiger Fehler keine Rolle.","richtig"]]viewof answers_3_4 =quizInput({questions: MC_3_4,options: ["richtig","falsch"]})Punkte_3_4 = {const Sum = (answers_3_4[0] == MC_3_4[0][1])*1+ (answers_3_4[1] == MC_3_4[1][1])*1+ (answers_3_4[2] == MC_3_4[2][1])*1+ (answers_3_4[3] == MC_3_4[3][1])*1var Punkte_3_4 = Sum -2if (Punkte_3_4 <1) {Punkte_3_4 =0}return(Punkte_3_4)}
Punkte:
MC 3.5.
MC 3.5: Sind folgende Aussagen richtig oder falsch?
MC_3_5 = [ ["Die Normalverteilung der Residuen schaut man sich in Statistikpaketen visuel an.","richtig"], ["Wenn ein b nicht signifikant ist, dann gibt es keine Beziehung zwischen zwei Variablen.","falsch"], ["Die Linearität der Beziehungen ist eine Eigenschaft jeder UV auf die AV.","richtig"], ["Der VIF gibt an, um welchen Faktor die Fehlervarianz bei Multikollinearität grösser ist, als ohne Multikollinearität.","richtig"]]viewof answers_3_5 =quizInput({questions: MC_3_5,options: ["richtig","falsch"]})Punkte_3_5 = {const Sum = (answers_3_5[0] == MC_3_5[0][1])*1+ (answers_3_5[1] == MC_3_5[1][1])*1+ (answers_3_5[2] == MC_3_5[2][1])*1+ (answers_3_5[3] == MC_3_5[3][1])*1var Punkte_3_5 = Sum -2if (Punkte_3_5 <1) {Punkte_3_5 =0}return(Punkte_3_5)}
Punkte:
MC 3.6.
MC 3.6: Sind folgende Aussagen richtig oder falsch?
MC_3_6 = [ ["Wenn eine UV wenig Varianz hat, ist der Standardfehler seines Regressionskoeffizienten gross.","richtig"], ["Je grösser die Multikollinearität zwischen einer UV und den übrigen Variablen im Modell, desto grösser der Standardfehler seines Regressionskoeffizienten.","richtig"], ["Der VIF ist umgekehrt proportinal zum TOL.","richtig"], ["Wenn man die Fallzahl der Stichprobe verdoppelt, halbieren sich die Standardfehler der b's.","falsch"]]viewof answers_3_6 =quizInput({questions: MC_3_6,options: ["richtig","falsch"]})Punkte_3_6 = {const Sum = (answers_3_6[0] == MC_3_6[0][1])*1+ (answers_3_6[1] == MC_3_6[1][1])*1+ (answers_3_6[2] == MC_3_6[2][1])*1+ (answers_3_6[3] == MC_3_6[3][1])*1var Punkte_3_6 = Sum -2if (Punkte_3_6 <1) {Punkte_3_6 =0}return(Punkte_3_6)}
Insgesamt von Punkten, was % und etwa einer entspricht.
LEF 5
Essayfragen 5
E5.1 Was ist eine Dummyvariable?
E5.2 Wie viele Dummyvariablen brauchen Sie, um die volle Information einer kategorialen Variablen mit vier Ausprägungen abzubilden?
E5.3 Wie würden Sie eine kategoriale UV mit drei Ausprägungen in einer Regressionsgleichung darstellen?
E5.4 Wenn eine Kovariate in einer Regression unterschiedliche Mittelwerte für zwei Gruppen haben soll, wie würden Sie die Regressionsgleichung aufstellen?
E5.5 Was sagt in einer Regression mit einer Dummy als UV a) das \(b_1\) und b) das \(b_2\) aus?
E5.6 Was sagt in einer Regression mit einer Dummy und eine metrischen Variablen das \(b_2\) der Dummy aus?
MC-Fragen 5
MC 5.1.
MC 5.1: Sind folgende Aussagen richtig oder falsch?
MC_5_1 = [ ["Dummyvariablen haben immer die Ausprägungen 1 und 2.","falsch"], ["In einer Regression mit einer Dummy als UV, gibt das b2 den Mittelwertunterschied der AV wieder","richtig"], ["Baut man für jeder Ausprägung einer kategorialen UV eine Dummy, kann die Regression nicht berechnet werden.","richtig"], ["Bei einer Regression mit einer Dummyvariablen, gibt die Konstante b1 den Mittelwert der 0-Gruppe wieder.","richtig"]]viewof answers_5_1 =quizInput({questions: MC_5_1,options: ["richtig","falsch"]})Punkte_5_1 = {const Sum = (answers_5_1[0] == MC_5_1[0][1])*1+ (answers_5_1[1] == MC_5_1[1][1])*1+ (answers_5_1[2] == MC_5_1[2][1])*1+ (answers_5_1[3] == MC_5_1[3][1])*1var Punkte_5_1 = Sum -2if (Punkte_5_1 <1) {Punkte_5_1 =0}return(Punkte_5_1)}
Punkte:
MC 5.2.
MC 5.2: Sind folgende Aussagen richtig oder falsch?
MC_5_2 = [ ["R macht aus einer kategorialen Variablen (aka Faktor) immer genausoviele Dummys, wie der Faktor Ausprägungen hat.","falsch"], ["Der t-Test einer Dummyvariablen prüft, ob es einen Mittelwertunterschied zwischen den beiden Gruppen gibt.","richtig"], ["Liegt der p-Wert einer Dummy über .05, ist der Mittelwertunterschied zwischen den Gruppen nicht signifikant.","richtig"], ["Das BETA einer Dummyvariablen ist nicht interpretierbar.","falsch"]]viewof answers_5_2 =quizInput({questions: MC_5_2,options: ["richtig","falsch"]})Punkte_5_2 = {const Sum = (answers_5_2[0] == MC_5_2[0][1])*1+ (answers_5_2[1] == MC_5_2[1][1])*1+ (answers_5_2[2] == MC_5_2[2][1])*1+ (answers_5_2[3] == MC_5_2[3][1])*1var Punkte_5_2 = Sum -2if (Punkte_5_2 <1) {Punkte_5_2 =0}return(Punkte_5_2)}
Punkte:
MC 5.3.
MC 5.3: Sind folgende Aussagen richtig oder falsch?
MC_5_3 = [ ["Bestehen in einer Regression die UVs aus einer Dummy und zwei metrischen Variablen, ergeben sich zwei Ebenen, die sich nicht berühren.","richtig"], ["In einer Regression mit einem Faktor der drei Ausprägungen hat und einer metrischen Variablen, haben die drei Gruppen unterschiedliche Anstiege.","falsch"], ["Besteht eine Regression aus zwei Dummys für eine kategoriale mit drei Ausprägungen, kann Multikollinearität ausgeschlossen werden.","falsch"], ["In R kann man einen Faktor einfach so in eine Regressionsgleichung tun, also z.B. lm(Y ~ Faktor, data = DATEN)","richtig"]]viewof answers_5_3 =quizInput({questions: MC_5_3,options: ["richtig","falsch"]})Punkte_5_3 = {const Sum = (answers_5_3[0] == MC_5_3[0][1])*1+ (answers_5_3[1] == MC_5_3[1][1])*1+ (answers_5_3[2] == MC_5_3[2][1])*1+ (answers_5_3[3] == MC_5_3[3][1])*1var Punkte_5_3 = Sum -2if (Punkte_5_3 <1) {Punkte_5_3 =0}return(Punkte_5_3)}
Punkte:
MC 5.4.
MC 5.4: Sind folgende Aussagen richtig oder falsch?
MC_5_4 = [ ["Hat man zwei unabhängige Dummys (zB Geschlecht und Abstimmungsteilnahme) in einem Modell, gibt es zwei Referenzkategorien.","richtig"], ["Ist die AV eine Dummyvariable, gibt das b1 den Mittelwertunterschied zwischen den UV-Gruppen wieder.","falsch"], ["Ist die AV eine Dummyvariable, wird in der Regel eine logistische Regression gerechnet.","richtig"], ["Hat man zwei metrische Variablen als UVs, müssen sie in zwei Dummys umkodiert werden.","falsch"]]viewof answers_5_4 =quizInput({questions: MC_5_4,options: ["richtig","falsch"]})Punkte_5_4 = {const Sum = (answers_5_4[0] == MC_5_4[0][1])*1+ (answers_5_4[1] == MC_5_4[1][1])*1+ (answers_5_4[2] == MC_5_4[2][1])*1+ (answers_5_4[3] == MC_5_4[3][1])*1var Punkte_5_4 = Sum -2if (Punkte_5_4 <1) {Punkte_5_4 =0}return(Punkte_5_4)}
Punkte:
MC 5.5.
MC 5.5: Sind folgende Aussagen richtig oder falsch?
MC_5_5 = [ ['Das Simpsons-Paradox stammt von der Serie "Die Simpsons"',"falsch"], ["Das Simpsons-Paradox gründet auf der Unterspezifikation eines Modells.","richtig"], ["Das Simpsons-Paradox erklärt, warum bei Gruppenvergleichen die Homerskedastizität keine Rolle spielt.","falsch"], ["Das Simpsons-Paradox erklärt, warum man zu falschen Schlüssen kommt, wenn man Gruppenunterschiede nicht berücksichtigt","richtig"]]viewof answers_5_5 =quizInput({questions: MC_5_5,options: ["richtig","falsch"]})Punkte_5_5 = {const Sum = (answers_5_5[0] == MC_5_5[0][1])*1+ (answers_5_5[1] == MC_5_5[1][1])*1+ (answers_5_5[2] == MC_5_5[2][1])*1+ (answers_5_5[3] == MC_5_5[3][1])*1var Punkte_5_5 = Sum -2if (Punkte_5_5 <1) {Punkte_5_5 =0}return(Punkte_5_5)}
Insgesamt von Punkten, was % und etwa einer entspricht.
LEF 6
Essayfragen 6
E6.1 Was ist eine Slope-Dummy-Variable?
E6.2 Wenn Sie die Hypothese haben, dass der Nachrichtenfaktor «Personalsierung» stärker wirkt, je älter die Befragten sind, wie würden Sie das Regressionsmodell formulieren (Gleichung)? Sie können auch die Modellschreibweise von R verwenden, also lm().
Formel-Lösung E6.2
E6.3 Warum ist beim Rechnen mit Slope-Dummys die Multikollinearität ein besonderes Problem? Wie können Sie das bei Slope-Dummys (und nur hier) lösen?
E6.4 Zeichnen Sie ein typisches Beispiel für einen Zusammenhang, den man mit einer Slope-Dummy modellieren würde. (Tipp: Es braucht ein Koordinatensystem und dann zeichnen Sie da Punkte mit unterschiedlichen Farben und Regressionsgeraden rein.)
Lösung E6.4
E6.5 (war fast wie 6.3 und wurde mit ihr zusammengelegt)
E6.6 Wie bilden Sie in R eine Slope-Dummy (Interaktion zwischen einer Dummy und einer Metrischen)
MC-Fragen 6
MC 6.1.
MC 6.1: Sind folgende Aussagen richtig oder falsch?
MC_6_1 = [ ["Eine Slope-Dummy ist eine Interaktion","richtig"], ["Slope-Dummys geben den Anstieg der Dummyvariablen wieder.","falsch"], ["Interaktionen von Variablen werden als Produkt der Variablen gebaut.","richtig"], ["In R müssen die Interaktionen als Differntialgleichung erstellt werden.","falsch"]]viewof answers_6_1 =quizInput({questions: MC_6_1,options: ["richtig","falsch"]})Punkte_6_1 = {const Sum = (answers_6_1[0] == MC_6_1[0][1])*1+ (answers_6_1[1] == MC_6_1[1][1])*1+ (answers_6_1[2] == MC_6_1[2][1])*1+ (answers_6_1[3] == MC_6_1[3][1])*1var Punkte_6_1 = Sum -2if (Punkte_6_1 <1) {Punkte_6_1 =0}return(Punkte_6_1)}
Punkte:
MC 6.2.
MC 6.2: Sind folgende Aussagen richtig oder falsch?
MC_6_2 = [ ["Wenn man Interaktionen im Modell hat, müssen auch immer die Haupteffekte im Modell sein.","richtig"], ["Wenn man Slope-Dummys baut, muss die Referenzkategorie mit in das Modell.","falsch"], ["Das b_1 einer Regression mit Slope-Dummy gibt den Mittelwert für die 0-Gruppe wieder.","falsch"], ["Das BETA einer Slope-Dummy ist nicht interpretierbar.","falsch"]]viewof answers_6_2 =quizInput({questions: MC_6_2,options: ["richtig","falsch"]})Punkte_6_2 = {const Sum = (answers_6_2[0] == MC_6_2[0][1])*1+ (answers_6_2[1] == MC_6_2[1][1])*1+ (answers_6_2[2] == MC_6_2[2][1])*1+ (answers_6_2[3] == MC_6_2[3][1])*1var Punkte_6_2 = Sum -2if (Punkte_6_2 <1) {Punkte_6_2 =0}return(Punkte_6_2)}
Punkte:
MC 6.3.
MC 6.3: Sind folgende Aussagen richtig oder falsch?
MC_6_3 = [ ["Bestehen in einer Regression die UVs aus einer Dummy und zwei metrischen Variablen, ergeben sich zwei Ebenen, die sich nicht berühren.","richtig"], ["In einer Regression mit einem Faktor der drei Ausprägungen hat und einer metrischen Variablen, haben die drei Gruppen unterschiedliche Anstiege.","falsch"], ["Die hohe (technische) Multikollinearität durch Dummyvariablen lässt sich durch z-Transformation der metrischen UVs reduzieren.","richtig"], ["In R würde eine Slope-Dummy nach folgendem Schema gebaut: lm(AV ~ Dummy + Metrische + Dummy * Metrische, data = DATEN)","richtig"]]viewof answers_6_3 =quizInput({questions: MC_6_3,options: ["richtig","falsch"]})Punkte_6_3 = {const Sum = (answers_6_3[0] == MC_6_3[0][1])*1+ (answers_6_3[1] == MC_6_3[1][1])*1+ (answers_6_3[2] == MC_6_3[2][1])*1+ (answers_6_3[3] == MC_6_3[3][1])*1var Punkte_6_3 = Sum -2if (Punkte_6_3 <1) {Punkte_6_3 =0}return(Punkte_6_3)}
Punkte:
MC 6.4.
MC 6.4: Sind folgende Aussagen richtig oder falsch?
MC_6_4 = [ ["Wenn das b einer Slope-Dummy negativ ist, hat die 1-Gruppe einen tieferen Anstieg als die 0-Gruppe.","richtig"], ["Wenn es im Modell eine Slope-Dummy gibt, ist das b der Dummy nicht mehr der Mittelwertunterschied zwischen den Gruppen.","richtig"], ["Zwei metrische Variablen können auch einen Interaktionseffekt haben.","richtig"], ["Gibt es drei UV, kann jede mit jeder und alle zusammen Interaktionseffekte haben.","richtig"]]viewof answers_6_4 =quizInput({questions: MC_6_4,options: ["richtig","falsch"]})Punkte_6_4 = {const Sum = (answers_6_4[0] == MC_6_4[0][1])*1+ (answers_6_4[1] == MC_6_4[1][1])*1+ (answers_6_4[2] == MC_6_4[2][1])*1+ (answers_6_4[3] == MC_6_4[3][1])*1var Punkte_6_4 = Sum -2if (Punkte_6_4 <1) {Punkte_6_4 =0}return(Punkte_6_4)}
Punkte:
MC 6.5.
MC 6.5: Sind folgende Aussagen richtig oder falsch?
MC_6_5 = [ ['Gibt es nur eine metrische UV, muss diese in mehrere Dummys umkodiert werden, um Slope-Dummys bauen zu können.',"falsch"], ["Wenn eine Slope-Dummy signifikant ist, hat die 1-Gruppe immer einen signifikant von 0 verschiedenen Anstieg.","falsch"], ["Wenn die Dummy-Variable, die für eine Slope-Dummy verwendet werden soll, mehr als 5 Ausprägungen hat, dann kann sie auch als metrisch betrachtet werden.","falsch"], ["Beim R-Output zu Regressionskoeffizienten haben viele Pakete verschiedene Kennzeichnungen. Man muss also sehr genau hinschauen, was womit gemeint ist.","richtig"]]viewof answers_6_5 =quizInput({questions: MC_6_5,options: ["richtig","falsch"]})Punkte_6_5 = {const Sum = (answers_6_5[0] == MC_6_5[0][1])*1+ (answers_6_5[1] == MC_6_5[1][1])*1+ (answers_6_5[2] == MC_6_5[2][1])*1+ (answers_6_5[3] == MC_6_5[3][1])*1var Punkte_6_5 = Sum -2if (Punkte_6_5 <1) {Punkte_6_5 =0}return(Punkte_6_5)}
Insgesamt von Punkten, was % und etwa einer entspricht.
LEF 8
Essayfragen 8
E8.1 Bitte schauen Sie sich die folgenden drei (mistigen) Tabellen an, die aus fiktiven Publikationen stammen. Jedes mal werden die Koeffizienten als «beta» bezeichnet, aber es könnten nur die unstandardisierten Regressionskoeffizienten b sein oder die standardisierten Regressionskoeffizienten std. b. Was ist wohl was? a) Begründen Sie Ihre Entscheidung! b) Eklären Sie, warum es nicht \(\beta\)s sein können.
Essayfragen 8.2-8.3
E8.2 Schreiben Sie zu jedem der folgenden Schlagworte in ganzen Sätzen auf, zu welchen Zwecken Faktorenanalysen alles eingesetzt werden können: a) latente Variablen entdecken b) Multikollinearität c) Indices d) Messung latenter Konstrukte
E8.3 a) Erklären Sie, was Faktorladungen sind. b) Wie gehen Sie vor, wenn Sie Faktorladungen interpretieren wollen?
Essayfragen 8.4-8.10
Lesen Sie @song2004 und beantworten Sie dann folgende Fragen und die anschliessenden MCs.
E8.4 Was wird mit Cronbachs \(\alpha\) beschrieben?
E8.5 Was für eine Faktorenanalyse haben Song et al durchgeführt?
E8.6 Mit welcher Methoden wurden die Faktoren rotiert?
E8.7 Wie viele initiale Faktoren hat die Faktorenanalyse herausgegeben?
E8.8 a) Nach welchen Kriterien wurden die Faktoren ausgewählt? b) Wie bewerten Sie das Vorgehen?
E8.9 a) Wie viele Items (Fragen) wurden mit der Faktorenanalyse ausgewertet? b) Auf wie viele Faktoren wurden die Items reduziert?
E8.10 Wie viel Varianz erklären die Faktoren, die von Song et al ausgewählt wurden?
MC-Fragen 8
MC 8.1.
MC 8.1: Was sagen die Zahlen im Text von @song2004?
MC_8_1 = [ ["Die Variablen erklären 67.4 Prozent der extrahierten Faktoren.","falsch"], ["Die Faktoren wurden mit Hilfe der Varimax-Methode rotiert.","richtig"], ["Alle Faktoren zeigen ein hohes Cronbachs α.","falsch"], ['Der "Factor 5" erklärt etwa das Vierfache einer einfachen Variable.',"falsch"]]viewof answers_8_1 =quizInput({questions: MC_8_1,options: ["richtig","falsch"]})Punkte_8_1 = {const Sum = (answers_8_1[0] == MC_8_1[0][1])*1+ (answers_8_1[1] == MC_8_1[1][1])*1+ (answers_8_1[2] == MC_8_1[2][1])*1+ (answers_8_1[3] == MC_8_1[3][1])*1var Punkte_8_1 = Sum -2if (Punkte_8_1 <1) {Punkte_8_1 =0}return(Punkte_8_1)}
Punkte:
MC 8.2.
MC 8.2: Was sagen die Zahlen im Text von @song2004?
MC_8_2 = [ ['Der "Factor 1" erklärt die meiste Varianz der ursprünglichen Variablen.',"richtig"], ['Da auf "Factor 3" und "Factor 4" gleich viele Variablen laden, haben Sie dieselbe Varianzaufklärung.',"falsch"], ["Wenn der Eigenwert eines Faktors für einen Faktor A grösser ist als bei Faktor B, muss bei A Cronbach α auch grösser sein als bei B.","falsch"], ["In der Korrelationstabelle sind die Faktoren abgebildet, die teilweise stark korrelieren.","falsch"]]viewof answers_8_2 =quizInput({questions: MC_8_2,options: ["richtig","falsch"]})Punkte_8_2 = {const Sum = (answers_8_2[0] == MC_8_2[0][1])*1+ (answers_8_2[1] == MC_8_2[1][1])*1+ (answers_8_2[2] == MC_8_2[2][1])*1+ (answers_8_2[3] == MC_8_2[3][1])*1var Punkte_8_2 = Sum -2if (Punkte_8_2 <1) {Punkte_8_2 =0}return(Punkte_8_2)}
Punkte:
MC 8.3.
MC 8.3: Was sagen die Zahlen im Text von @song2004?
MC_8_3 = [ ["In Tabelle 3 sind die βs der GG angegeben, die mit den b's in der Stichprobe geschätzt wurden.","falsch"], ["Die standardisierten BETAS sind mit den Korrelationswerten der Tabelle 2 vergleichbar. ","richtig"], ["Die Varianzaufklärung der Regression beträgt 54 Prozent.","falsch"], ['Der p-Wert von "Virutal community" ist genau 0.',"falsch"]]viewof answers_8_3 =quizInput({questions: MC_8_3,options: ["richtig","falsch"]})Punkte_8_3 = {const Sum = (answers_8_3[0] == MC_8_3[0][1])*1+ (answers_8_3[1] == MC_8_3[1][1])*1+ (answers_8_3[2] == MC_8_3[2][1])*1+ (answers_8_3[3] == MC_8_3[3][1])*1var Punkte_8_3 = Sum -2if (Punkte_8_3 <1) {Punkte_8_3 =0}return(Punkte_8_3)}
Punkte:
MC 8.4.
MC 8.4: Was sagen die Zahlen im Text von @song2004?
MC_8_4 = [ ["Je stärker Studierende versuchen sich in eine «Virtuelle community» zu integrieren, desto eher werden sie internetsüchtig.","richtig"], ["Multikollinearität in den UVs kann ausgeschlossen werden.","falsch"], ["Wer das Internet nutzt, um Informationen zu suchen, gerät eher nicht in eine Internetsucht.","richtig"], ["Wer das Internet nutzt, um seinen «Personal status» zu verbessern, neigt stark zu Internetsucht.","falsch"]]viewof answers_8_4 =quizInput({questions: MC_8_4,options: ["richtig","falsch"]})Punkte_8_4 = {const Sum = (answers_8_4[0] == MC_8_4[0][1])*1+ (answers_8_4[1] == MC_8_4[1][1])*1+ (answers_8_4[2] == MC_8_4[2][1])*1+ (answers_8_4[3] == MC_8_4[3][1])*1var Punkte_8_4 = Sum -2if (Punkte_8_4 <1) {Punkte_8_4 =0}return(Punkte_8_4)}
Punkte:
MC 8.5.
MC 8.6: Was ist im Kontext der Faktorenanalyse richtig und was ist falsch?
MC_8_5 = [ ['Bei obliquer Rotation können die Faktoren am Ende etwas korrelieren.',"richtig"], ["Eine PCA mit orthogonaler Rotation ist leichter zu interpretieren und oblique realistischer.","richtig"], ["Eigenvalues zeigen an, wie viel Varianz der Faktoren durch die UVs erklärt wird.","falsch"], ["Die Anzahl der Faktoren einer PCA ist in der Regel grösser als die Anzahl der Variablen, mit denen die PCA durchgeführt wird.","falsch"]]viewof answers_8_5 =quizInput({questions: MC_8_5,options: ["richtig","falsch"]})Punkte_8_5 = {const Sum = (answers_8_5[0] == MC_8_5[0][1])*1+ (answers_8_5[1] == MC_8_5[1][1])*1+ (answers_8_5[2] == MC_8_5[2][1])*1+ (answers_8_5[3] == MC_8_5[3][1])*1var Punkte_8_5 = Sum -2if (Punkte_8_5 <1) {Punkte_8_5 =0}return(Punkte_8_5)}
Punkte:
MC 8.6.
MC 8.6: Was ist im Kontext der Faktorenanalyse richtig und was ist falsch?
MC_8_6 = [ ['Wenn die Korrelationen immer innerhalb von Variablengruppen hoch sind, dann gibt es bei einer Faktorenanalyse eine gute Lösung.',"richtig"], ["Faktorenanalysen (PCA) kann man auch gut für die Indexbildung einsetzen.","richtig"], ["Faktorladungen einer PCA sind die Korrelationen zwischen den Variablen und den Faktoren.","falsch"], ["Nach einer orthogonalen Rotation sind die Faktoren PCA am Ende unkorreliert.","richtig"]]viewof answers_8_6 =quizInput({questions: MC_8_6,options: ["richtig","falsch"]})Punkte_8_6 = {const Sum = (answers_8_6[0] == MC_8_6[0][1])*1+ (answers_8_6[1] == MC_8_6[1][1])*1+ (answers_8_6[2] == MC_8_6[2][1])*1+ (answers_8_6[3] == MC_8_6[3][1])*1var Punkte_8_6 = Sum -2if (Punkte_8_6 <1) {Punkte_8_6 =0}return(Punkte_8_6)}
Insgesamt (nur MCs) von Punkten, was % und etwa einer entspricht.
LEF 10
Essayfragen 10
E10.1 Was bedeuten die Exp(B) in der logistischen Regression?
E10.2 Wenn eine AV aus einer kategorialen Variable besteht mit drei Ausprägungen. Was muss man dann als Analyse damit machen?
E10.3 Die Voraussetzungen für eine normale Regression gelten auch bei der logistischen. Nennen Sie eine darüber hinausgehende Voraussetzung.
E10.4 Was bedeutet es, wenn ein Exp(B) einer logistischen Regression fast 0 ist?
E10.5 Wenn in einer Analyse die Wahlteilnahme die AV und die Frage, ob jemand Nachrichten konsumiert die UV ist, wie interpretieren Sie dann ein zugehöriges EXP(B) von 2?
E10.6 Schreiben Sie als Formel oder frei in Ihren Worten auf, was die ODDS-Ratio bedeutet.
E10.7 Was verbirgt sich hinter der Abkürzung «ML»?
E10.8 Wenn man in einem ML für das Trainingsmaterial nur einen Teil (sagen wir 70%) der gesammelten Daten nimmt, sind dann die b’s nicht verzerrt? Begründen Sie Ihre Antwort. Wenn sie es nicht sind, warum nimmt man dann nicht immer nur 70% der Daten? Das wäre doch billiger?
MC-Fragen 10
MC 10.1.
MC 10.1: Sind folgende Aussagen richtig oder falsch?
MC_10_1 = [ ["Die «Odds Ratio» (OR) und Exp(B) sind dasselbe.","richtig"], ["Logistische Regressionen werden gerechnet, wenn eine UV eine Dummy ist.","falsch"], ["Die OR geht von 1/∞ bis ∞.","richtig"], ["Ein Exp(B) von 1 ist ein perfekter Zusammenhang.","falsch"]]viewof answers_10_1 =quizInput({questions: MC_10_1,options: ["richtig","falsch"]})Punkte_10_1 = {const Sum = (answers_10_1[0] == MC_10_1[0][1])*1+ (answers_10_1[1] == MC_10_1[1][1])*1+ (answers_10_1[2] == MC_10_1[2][1])*1+ (answers_10_1[3] == MC_10_1[3][1])*1var Punkte_10_1 = Sum -2if (Punkte_10_1 <1) {Punkte_10_1 =0}return(Punkte_10_1)}
Punkte:
MC 10.2.
MC 10.2: Sind folgende Aussagen richtig oder falsch?
MC_10_2 = [ ["Eine OR < 0 zeigt an, dass die S-Kurve von oben nach unten verläuft.","falsch"], ["Sind UV und AV Dummys, zeigt ein EXP(B) > 1 das Vielfache an, um dass die Wahrscheinlichkeit der 1 in der AV grösser ist, wenn die UV 1 ist.","richtig"], ["Bei perfekter Separation kann die Logistische Regression nicht gerechnet werden","richtig"], ["Ist bei einer logistischen Regression das B signifikant, ist immer auch Exp(B) signifikant.","richtig"]]viewof answers_10_2 =quizInput({questions: MC_10_2,options: ["richtig","falsch"]})Punkte_10_2 = {const Sum = (answers_10_2[0] == MC_10_2[0][1])*1+ (answers_10_2[1] == MC_10_2[1][1])*1+ (answers_10_2[2] == MC_10_2[2][1])*1+ (answers_10_2[3] == MC_10_2[3][1])*1var Punkte_10_2 = Sum -2if (Punkte_10_2 <1) {Punkte_10_2 =0}return(Punkte_10_2)}
Punkte:
MC 10.3.
MC 10.3: Sind folgende Aussagen richtig oder falsch?
MC_10_3 = [ ["Soll eine kategoriale Variable mit mehreren Ausprägungen vorhergesagt werden, braucht es dafür Multinominale Modelle.","richtig"], ["Eine Multinominale Regression bedeutet im Grunde, dass für jede Ausprägung der AV eine logistische Regression gerechnet wird.","richtig"], ["Multinominale Regressionen werden gebraucht, wenn es nominale UV gibt.","falsch"], ["Multinominale Regressionen werden zu den GLM gezählt.","falsch"]]viewof answers_10_3 =quizInput({questions: MC_10_3,options: ["richtig","falsch"]})Punkte_10_3 = {const Sum = (answers_10_3[0] == MC_10_3[0][1])*1+ (answers_10_3[1] == MC_10_3[1][1])*1+ (answers_10_3[2] == MC_10_3[2][1])*1+ (answers_10_3[3] == MC_10_3[3][1])*1var Punkte_10_3 = Sum -2if (Punkte_10_3 <1) {Punkte_10_3 =0}return(Punkte_10_3)}
Punkte:
MC 10.4.
MC 10.4: Sind folgende Aussagen richtig oder falsch?
MC_10_4 = [ ["Während bei einer linearen Regression ein R2 von .5 gross wäre, ist das für ein ML deutlich zu klein.","richtig"], ["Beim Machine Learning mit Regressionen müssen die Voraussetzungen für OLS nicht geprüft werden.","falsch"], ["Die PCA wird im ML häufig eingesetzt, um Vorhersagen zu treffen.","falsch"], ["Beim ML gibt es viele andere Schätzmethoden als OLS.","richtig"]]viewof answers_10_4 =quizInput({questions: MC_10_4,options: ["richtig","falsch"]})Punkte_10_4 = {const Sum = (answers_10_4[0] == MC_10_4[0][1])*1+ (answers_10_4[1] == MC_10_4[1][1])*1+ (answers_10_4[2] == MC_10_4[2][1])*1+ (answers_10_4[3] == MC_10_4[3][1])*1var Punkte_10_4 = Sum -2if (Punkte_10_4 <1) {Punkte_10_4 =0}return(Punkte_10_4)}
Punkte:
MC 10.5.
MC 10.5: Sind folgende Aussagen richtig oder falsch?
MC_10_5 = [ ["Machine Learning wird mit ML abgekürzt.","richtig"], ["Es gibt supervised und unsupervised ML.","richtig"], ["Bei supervised ML wird immer mit Daten trainiert und dann an anderen Daten getestet.","richtig"], ["ML kann mit logistischen Regressionen gemacht werden, aber nicht mit OLS Regressionen.","falsch"]]viewof answers_10_5 =quizInput({questions: MC_10_5,options: ["richtig","falsch"]})Punkte_10_5 = {const Sum = (answers_10_5[0] == MC_10_5[0][1])*1+ (answers_10_5[1] == MC_10_5[1][1])*1+ (answers_10_5[2] == MC_10_5[2][1])*1+ (answers_10_5[3] == MC_10_5[3][1])*1var Punkte_10_5 = Sum -2if (Punkte_10_5 <1) {Punkte_10_5 =0}return(Punkte_10_5)}
Punkte:
MC 10.6.
MC 10.6: Mal was zu R?
MC_10_6 = [ ["Der Schlüsselbefehl für ein lineares Modell in R lautet: lm()","richtig"], ["Tidyverse ist ein Befehl, um R kleiner zu machen.","falsch"], ["R-Studio ist ein Programm, mit dem R gesteuert werden kann.","richtig"], ["Die Benennung von Kennwerten in R-Outputs ist über alle Pakete hinweg gleich.","falsch"]]viewof answers_10_6 =quizInput({questions: MC_10_6,options: ["richtig","falsch"]})Punkte_10_6 = {const Sum = (answers_10_6[0] == MC_10_6[0][1])*1+ (answers_10_6[1] == MC_10_6[1][1])*1+ (answers_10_6[2] == MC_10_6[2][1])*1+ (answers_10_6[3] == MC_10_6[3][1])*1var Punkte_10_6 = Sum -2if (Punkte_10_6 <1) {Punkte_10_6 =0}return(Punkte_10_6)}
Insgesamt von Punkten, was % und etwa einer entspricht.
LEF 12
Essayfragen 12
E12.1 a) Was ist das Ziel einer Clusteranalyse? b) Was ist der Unterschied zu einer Faktorenanalyse?
E12.2 Welches Skalenniveau wird benötigt, wenn bei einer Clusteranalyse «Clusterzentren» berechnet werdenn sollen?
E12.3 Wie ist der grobe Ablauf einer k-means-Clusteranalyse?
E12.4 Warum werden Clusteranalysen im Kontext von ML als «unsupervised learning» bezeichnet?
E12.5 Warum kann man nicht einfach sagen, dass die Clusterlösung mit der kleinsten Heterogenität (mittlere Distanz zu Clusterzentren) die beste Lösung ist?
E12.6 Warum werden oft Faktorenanalysen vor den Clusteranalysen durchgeführt?
E12.7 Was verbirgt sich hinter der Abkürzung «ML»?
E12.8 Wozu dient bei einer Clusteranalyse das «Ellbogenkriterium»?
E12.9 Warum sind hierarchische Clusteranalysen für Big Data oder zum Beispiel Bildanalysen ungeeignet?
E12.10 NEU Bringen Sie die folgenden Ablaufschritte einer hierarchischen Clusteranalyse in die richtige Reihenfolge:
Clusteralgorithmus wählen (single linkage)
Anzahl Cluster bestimmen (zB mit Dendrogramm)
Clustervariable(n) festlegen
jedem Fall ein Cluster bauen
den letzten Schritt so lange tun, bis es nur noch ein Cluster gibt
zwei Cluster zusammenlegen
Clusterlösung interpretieren
MC-Fragen 12
MC 12.1.
MC 12.1: Sind folgende Aussagen richtig oder falsch?
MC_12_1 = [ ["Clusteranalysen dienen der Zusammenfassung von Fällen in Gruppen.","richtig"], ["Mit Clusteranalysen werden Variablen zusammengefasst.","falsch"], ["Mit der Clusteranalyse werden möglichst unähnliche Fälle in Clustern zusammengefasst.","falsch"], ["Die Clusteranalyse ist ein exploratives Verfahren.","richtig"]]viewof answers_12_1 =quizInput({questions: MC_12_1,options: ["richtig","falsch"]})Punkte_12_1 = {const Sum = (answers_12_1[0] == MC_12_1[0][1])*1+ (answers_12_1[1] == MC_12_1[1][1])*1+ (answers_12_1[2] == MC_12_1[2][1])*1+ (answers_12_1[3] == MC_12_1[3][1])*1var Punkte_12_1 = Sum -2if (Punkte_12_1 <1) {Punkte_12_1 =0}return(Punkte_12_1)}
Punkte:
MC 12.2.
MC 12.2: Sind folgende Aussagen richtig oder falsch?
MC_12_2 = [ ["Die Clusteranalyse wird im ML-Kontext als «unsupervised learning» behandelt.","richtig"], ["Ziel der Clusteranalyse ist eine Reduktion der Fälle auf wenige untereinander homegene Cluster bei möglichst geringer Homogenität innerhalb der Cluster.","falsch"], ["Häufig werden Clusteranalysen vor Faktorenanalysen durchgeführt, damit letztere besser fitten.","falsch"], ["Damit die Variablen nicht hoch korrelieren, werden vor CAs oft FAs durchgeführt.","richtig"]]viewof answers_12_2 =quizInput({questions: MC_12_2,options: ["richtig","falsch"]})Punkte_12_2 = {const Sum = (answers_12_2[0] == MC_12_2[0][1])*1+ (answers_12_2[1] == MC_12_2[1][1])*1+ (answers_12_2[2] == MC_12_2[2][1])*1+ (answers_12_2[3] == MC_12_2[3][1])*1var Punkte_12_2 = Sum -2if (Punkte_12_2 <1) {Punkte_12_2 =0}return(Punkte_12_2)}
Punkte:
MC 12.3.
MC 12.3: Sind folgende Aussagen richtig oder falsch?
MC_12_3 = [ ["Clusteranalysen sind vor allem für die Analyse fehlender Werte geeignet.","falsch"], ["Es gibt Clusteranalyseverfahren, die mit allen möglichen Skalenniveaus gut klarkommen.","richtig"], ["Clusteranalysen funktionieren besonders gut mit kleinen Fallzahlen.","falsch"], ["Es kann immer höchstens so viele Cluster geben, wie es Variablen gibt.","falsch"]]viewof answers_12_3 =quizInput({questions: MC_12_3,options: ["richtig","falsch"]})Punkte_12_3 = {const Sum = (answers_12_3[0] == MC_12_3[0][1])*1+ (answers_12_3[1] == MC_12_3[1][1])*1+ (answers_12_3[2] == MC_12_3[2][1])*1+ (answers_12_3[3] == MC_12_3[3][1])*1var Punkte_12_3 = Sum -2if (Punkte_12_3 <1) {Punkte_12_3 =0}return(Punkte_12_3)}
Punkte:
MC 12.4.
MC 12.4: Sind folgende Aussagen richtig oder falsch?
MC_12_4 = [ ["Proximitätsmasse sind Ähnlichkeits- beziehungsweise Distanzmasse.","richtig"], ["Euklidische Distanzen können nur für metrische Variablen festgestellt werden.","richtig"], ["Für eine Clusteranalyse werden immer mindestens so viele Variablen benötigt, wie man Cluster extrahieren will.","falsch"], ["Manche Clusteralgorithmen nehmen als Ähnlichkeitsmass auch die Korrelation.","richtig"]]viewof answers_12_4 =quizInput({questions: MC_12_4,options: ["richtig","falsch"]})Punkte_12_4 = {const Sum = (answers_12_4[0] == MC_12_4[0][1])*1+ (answers_12_4[1] == MC_12_4[1][1])*1+ (answers_12_4[2] == MC_12_4[2][1])*1+ (answers_12_4[3] == MC_12_4[3][1])*1var Punkte_12_4 = Sum -2if (Punkte_12_4 <1) {Punkte_12_4 =0}return(Punkte_12_4)}
Punkte:
MC 12.5.
MC 12.5: Sind folgende Aussagen richtig oder falsch?
MC_12_5 = [ ["k-means-Cluster kann nur auf metrische (und Dummys) angewendet werden.","richtig"], ["Bei k-means-Cluster sind ähnliche Standardabweichungen der Variablen erwünscht.","richtig"], ["Bei k-means-cluster müssen hohe Korrelationen zwischen den Variablen vorliegen. ","falsch"], ["Mit dem Ellbogenkriterium werden Clusterzentren einander zugeordnet.","falsch"]]viewof answers_12_5 =quizInput({questions: MC_12_5,options: ["richtig","falsch"]})Punkte_12_5 = {const Sum = (answers_12_5[0] == MC_12_5[0][1])*1+ (answers_12_5[1] == MC_12_5[1][1])*1+ (answers_12_5[2] == MC_12_5[2][1])*1+ (answers_12_5[3] == MC_12_5[3][1])*1var Punkte_12_5 = Sum -2if (Punkte_12_5 <1) {Punkte_12_5 =0}return(Punkte_12_5)}
Punkte:
MC 12.6.
MC 12.6: Mal was zu R?
MC_12_6 = [ ["Clusteranalysen haben eher deskriptiven Analysegehalt.","richtig"], ["Clusteranalysen werden häufig eingesetzt um Typologien zu bilden.","richtig"], ["Hierarchische Clusteranalysen sind bei hohen Fallzahlen so rechenaufwendig, dass selbst moderne Rechner eher verrottet sind als sie mit der Analyse fertig werden.","richtig"], ["Die Clusterzentren der k-means-Cluster korrelieren hoch miteinander.","falsch"]]viewof answers_12_6 =quizInput({questions: MC_12_6,options: ["richtig","falsch"]})Punkte_12_6 = {const Sum = (answers_12_6[0] == MC_12_6[0][1])*1+ (answers_12_6[1] == MC_12_6[1][1])*1+ (answers_12_6[2] == MC_12_6[2][1])*1+ (answers_12_6[3] == MC_12_6[3][1])*1var Punkte_12_6 = Sum -2if (Punkte_12_6 <1) {Punkte_12_6 =0}return(Punkte_12_6)}