download.file(
"http://www.discoveringstatistics.com/docs/ds_data_files/SPSS%20Data%20Files/Video%20Games.sav",
"data/Video_Games.sav", quiet = TRUE)
DATEN <- haven::read_spss("data/Video_Games.sav")
head(DATEN)
## # A tibble: 6 × 4
## ID Aggression Vid_Games CaUnTs
## <dbl> <dbl> <dbl> <dbl>
## 1 69 13 16 0
## 2 55 38 12 0
## 3 7 30 32 0
## 4 96 23 10 1
## 5 130 25 11 1
## 6 124 46 29 16 GLM – Interaktionen
6.1 Die Folien zur Sitzung
Der Podcast
6.2 Interaktion mit Slope-Dummy
Eine Slope-Dummy ist ein Produkt aus einer metrischen Variable und einer Dummyvariabeblen. Durch diese Kombination wird es möglich, dass nicht nur der Mittelwert von zwei Gruppen unterschiedlich sein kann, sondern auch die Anstiege der Regressionsgeraden unterschiedlich sein können. Das bedeutet im Grunde, dass man prüfen kann, ob der Zusammenhang einer metrischen Variable für Gruppen unterschiedlich ist. Anders gesagt kann die Fragestellung beantwortet werden, ob zwei Gruppen sich in der Stärke des Zusammenhangs unterscheiden. Also zum Beispiel, ob ein Nachrichtenfaktor bei einer Rezipient:innengruppe anders wirkt (ein anderes Gewicht hat) als bei einer anderen Gruppe.
In der Grafik ist gut zu erkennen, dass die grüne Gruppe und die pinke Gruppe unterschiedliche Anstiege haben und damit die Lage der Werte besser abbilden kann, als würde man nur erlauben, dass die Mittelwerte unterschiedlich sind.
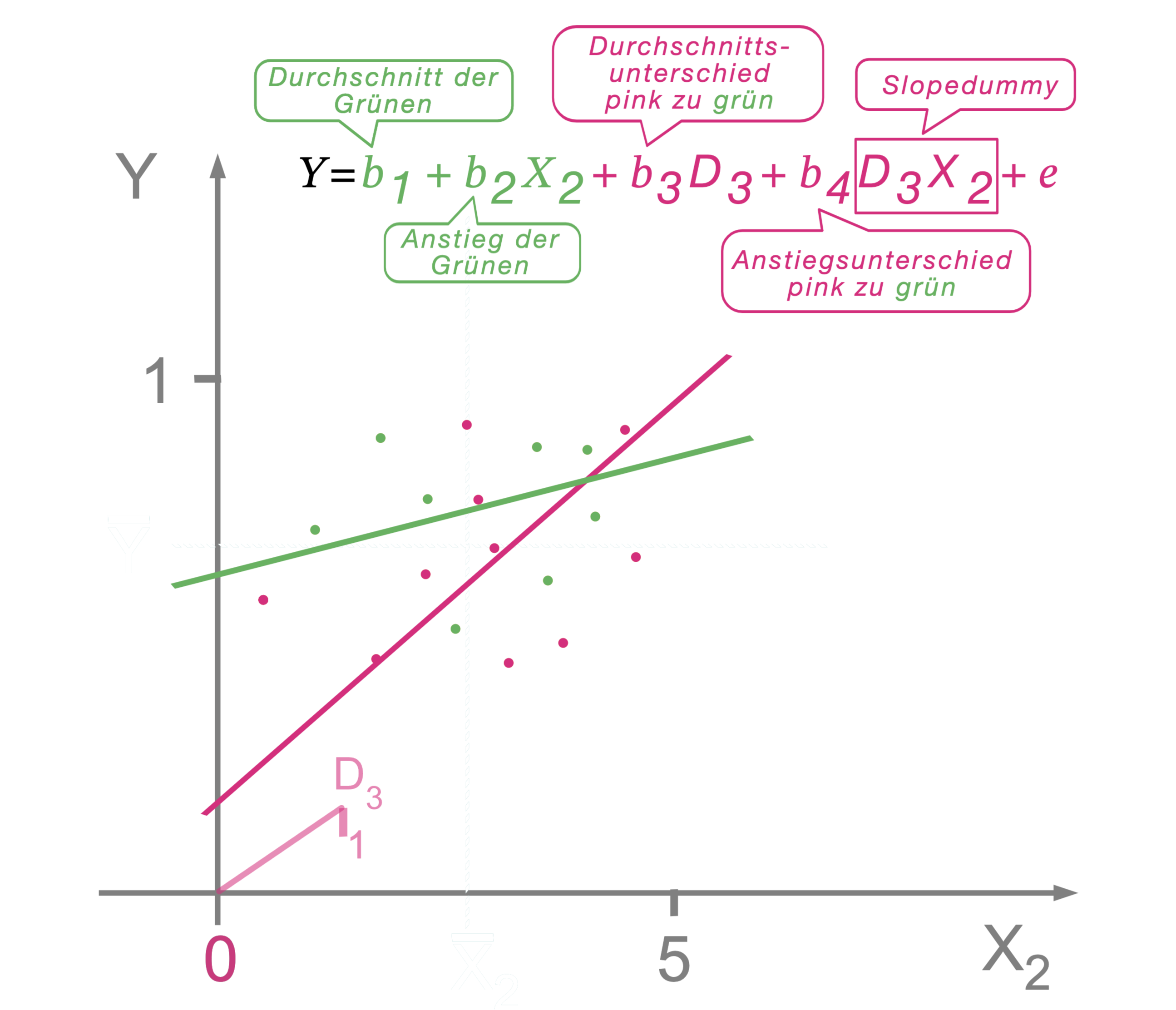
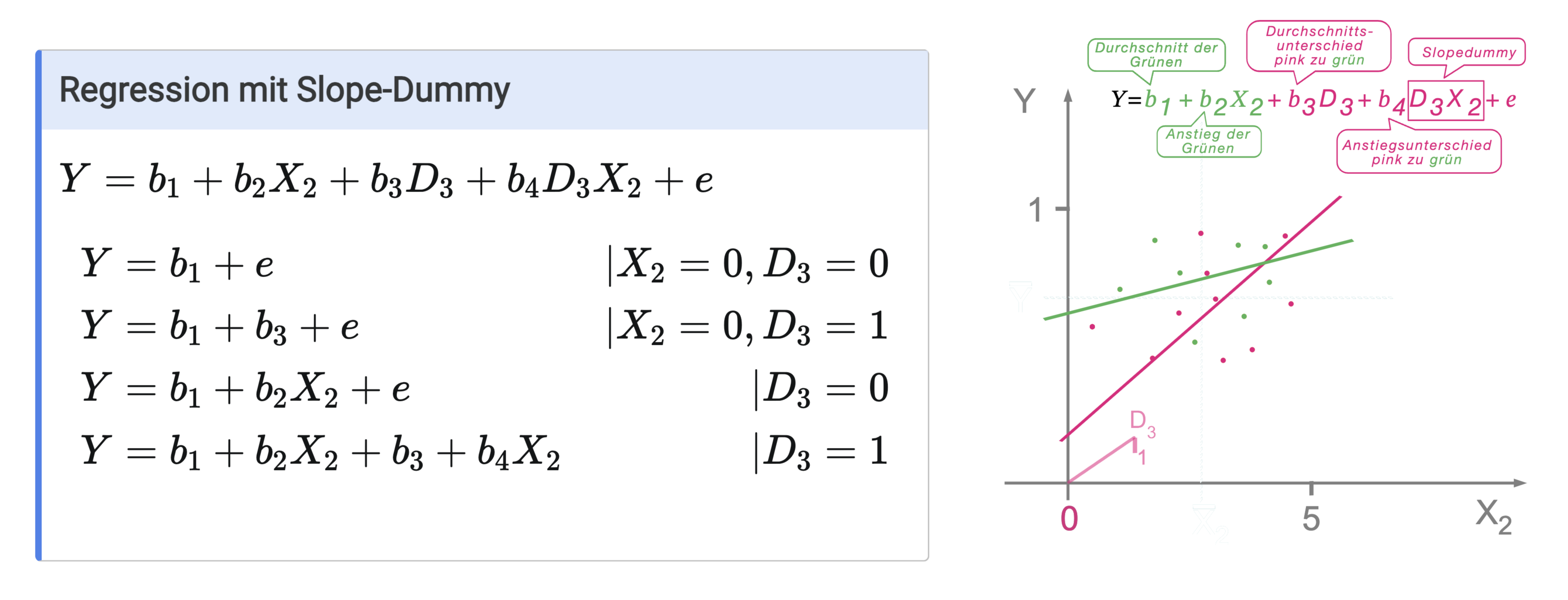
Das \(b_1\) steht für den Schnittpunkt mit der Y-Achse (\(X_2=\)) der 0-Gruppe (grün) und \(b_3\) für den Schnittpunkt der pinken mit der Y-Achse. Diese beiden Werte sind nicht ohne Weiteres interpretierbar und sorgen nur dafür, dass die Regressionsgeraden sich frei an die Werte der Gruppen anpassen könnnen. Interpretierbar wird das Ganze, wenn man die metrische Variable \(X_2\) zentriert, also in ihren Mittelwert verschiebt. Dann ist das \(b_1\) der Mittelwert der grünen 0-Gruppe und das \(b_3\) der Mittelwertunterschied zwischen der pinken 1-Gruppe und der 0-Gruppe.
In Worten bedeteutet das also:

Setzt man einzelne Werte gedanklich auf 0, wird die Formel jeweils klarer. Beachten Sie, dass auch das *1 weggelassen wird, wenn D = 1 ist.
6.3 Beispiel zu Videospielen und Aggression
Mit dem folgenden Beispiel läuft auch die Übung 2. Sie werden also selbst mit denselben Daten arbeiten. Dafür müssen sie zunächst geladen werden.
Wie Sie am Kopf der Datendatei sehen, besteht sie aus drei inhaltlichen Variablen und einer ID.
- Agression: wurde auf einer breit angelegten Skala gemessen.
- Vid_Games: wurde als Stunden pro Woche abgefragt.
- Antisoziales Varhalten wurde ebenfalls mit einer Skala gemessen und kann daher hohe Werte annehmen und ist metrisch.
6.4 Zusammenhang Videospiele und Aggression
Die Variable «CaUnTs» wird zunächst in einer kategoriale Variable umkodiert, wobei die 1 für geringes antisoziales Verhalten steht, die 2 für mittleres und die 3 für hohes. Ganz aggressionsfrei ist kaum jemand, aber etwa ein Viertel der Befragten zeigte eher tiefe Werte in der neu gebildeten Variable «Antisozial». Die meisten liegen in der Mitte (62%) und zum Glück nur wenige bei hohen Werten für antisoziales Verhalten (14%).
DATEN <- DATEN |>
mutate(Anti_Sozial = case_match(CaUnTs,
c(0:10) ~ 1,
c(11:30) ~ 2,
c(31:200) ~ 3,
.default = NA
)) |>
sjlabelled::var_labels(Anti_Sozial = "Antisoziales Verhalten")
DATEN |> sjmisc::frq(Anti_Sozial)
## Antisoziales Verhalten (Anti_Sozial) <numeric>
## # total N=442 valid N=442 mean=1.89 sd=0.61
##
## Value | N | Raw % | Valid % | Cum. %
## --------------------------------------
## 1 | 108 | 24.43 | 24.43 | 24.43
## 2 | 273 | 61.76 | 61.76 | 86.20
## 3 | 61 | 13.80 | 13.80 | 100.00
## <NA> | 0 | 0.00 | <NA> | <NA>R-Code
# Speichere in dem Datensatz Video_Games_AS_gering man nur die Fälle mit mittlerer
# oder geringem Antisozialem Verhalten.
Video_Games_AS_gering <- DATEN |>
filter(CaUnTs < 31)
# Mache einen Scatterplot (geom_point) für Vid_Games und Agression, unterteilt nach
# Anti_Sozial und lege da mit geom_smooth jeweils eine Regressionsgerade rein.
Video_Games_AS_gering |>
ggplot2::ggplot(aes(x = Vid_Games, y = Aggression, color = as.factor(Anti_Sozial))) +
geom_point()+
scale_color_manual(values=c(c(Farben[3], Farben[4]))) +
geom_smooth(method=lm, se=FALSE, fullrange=TRUE) +
theme_minimal()
## `geom_smooth()` using formula = 'y ~ x'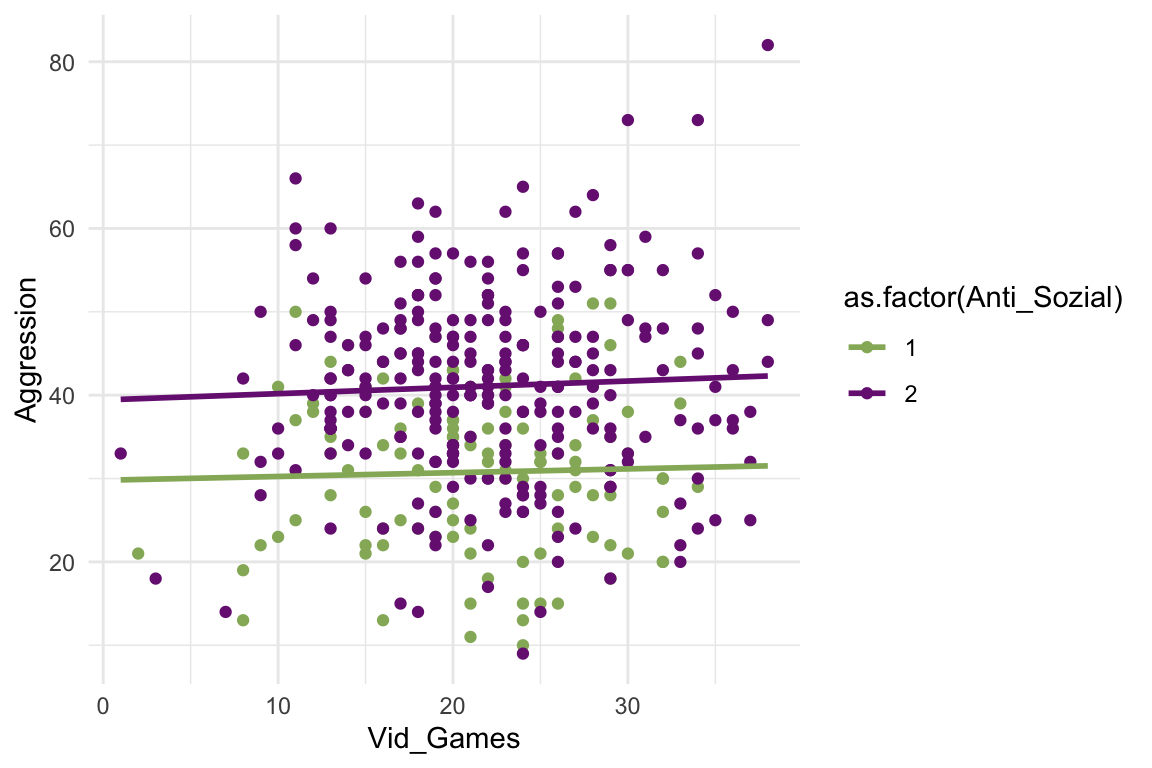
In der Grafik sind die Punktverteilungen gut zu sehen und auch, dass die Gruppe mit hohem Werten in «Antisozial» einen deutlich stärkeren Zusammenhang zwischen der Nutzung von Videospielen und Aggression zeigen.
[Mehr wird hier erstm nicht gespoilert, weil die Interpreltationen der Werte Teil der Übung sind 😃]
6.4.1 Grafik Videogames
R-Chunk
DATEN <- DATEN |>
mutate(Anti_Soz_hoch = case_match(Anti_Sozial,
3 ~ 1,
.default = 0
),
Anti_Soz_mittel = case_match(Anti_Sozial,
2 ~ 1,
.default = 0))
DATEN |> sjmisc::frq(Anti_Soz_hoch)
## Anti_Soz_hoch <numeric>
## # total N=442 valid N=442 mean=0.14 sd=0.35
##
## Value | N | Raw % | Valid % | Cum. %
## --------------------------------------
## 0 | 381 | 86.20 | 86.20 | 86.20
## 1 | 61 | 13.80 | 13.80 | 100.00
## <NA> | 0 | 0.00 | <NA> | <NA>
DATEN |>
ggplot2::ggplot(aes(x = Vid_Games, y = Aggression,
color = as.factor(Anti_Soz_hoch))) +
geom_point()+
scale_color_manual(values=c(c(Farben[3], Farben[4]))) +
geom_smooth(method=lm, se=FALSE, fullrange=TRUE) +
theme_minimal()
## `geom_smooth()` using formula = 'y ~ x'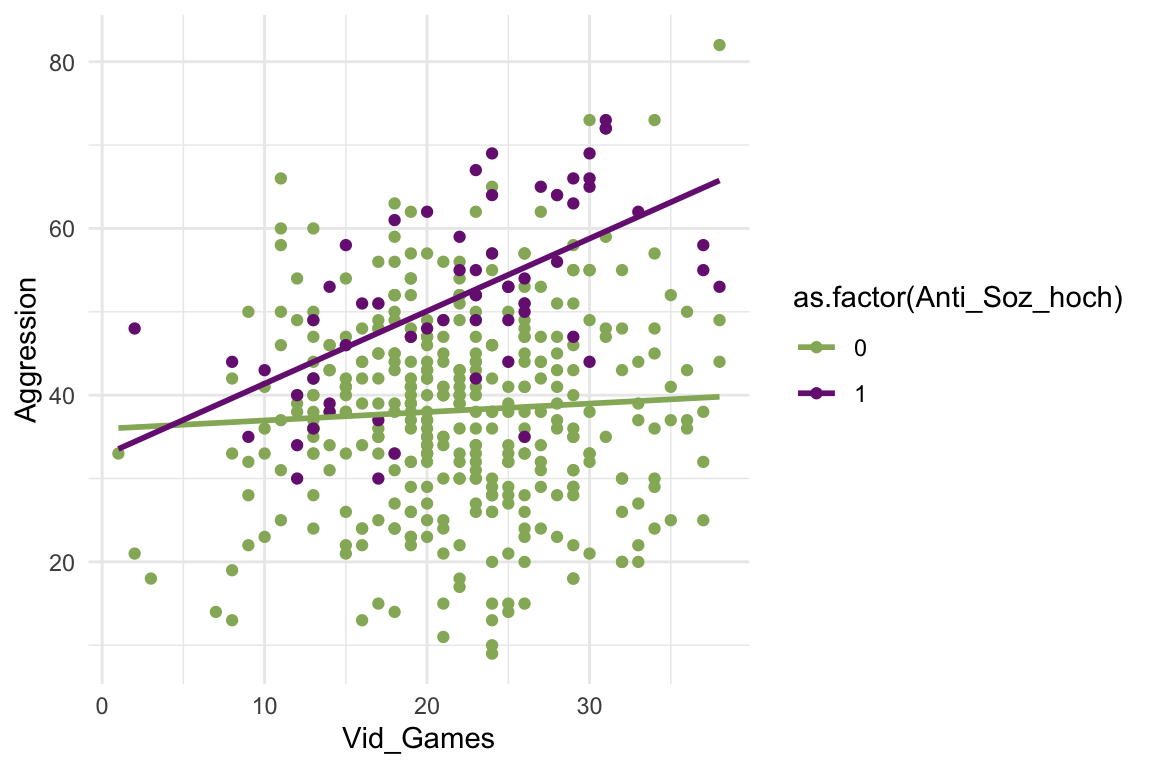
6.4.2 Multikollinearität bei Slope-Dummys und Lösungsansätze
6.5 Regression (unzentriert)
R-Chunk
Modell4 <- lm(Aggression ~ Vid_Games + Vid_Games * Anti_Soz_hoch, data = DATEN)
olsrr::ols_vif_tol(Modell4)
## Variables Tolerance VIF
## 1 Vid_Games 0.8318770 1.202101
## 2 Anti_Soz_hoch 0.1049793 9.525692
## 3 Vid_Games:Anti_Soz_hoch 0.1024746 9.758512
sjPlot::tab_model(Modell4,
show.ci = FALSE,
show.std = TRUE, # zeige die standardisierten Koeffizienten
show.est = TRUE, # zeige die unstandardisierten estimates
show.r2 = TRUE # zeige R^2
)| Agression | ||||
| Predictors | Estimates | std. Beta | p | std. p |
| (Intercept) | 35.95 | -0.00 | <0.001 | 0.968 |
| Video Games(Hours per week) |
0.10 | 0.11 | 0.238 | 0.008 |
| Anti Soz hoch | -3.28 | 0.37 | 0.501 | <0.001 |
| Vid_Games:Anti_Soz_hoch | 0.77 | 0.15 | <0.001 | <0.001 |
| Observations | 442 | |||
| R2 / R2 adjusted | 0.183 / 0.177 | |||
6.6 Regression nach Zentrierung
R-Chunk
DATEN |>
summarize(Aggressions_Mittel = mean(Aggression, na.rm = TRUE), .by = Anti_Soz_hoch)
## # A tibble: 2 × 2
## Anti_Soz_hoch Aggressions_Mittel
## <dbl> <dbl>
## 1 0 38.2
## 2 1 51.9
51.9 - 38.2
## [1] 13.7
# zentriere Vid_Games (Mittelwert = 0):
DATEN_z <- DATEN %>%
mutate(Vid_Games = Vid_Games - mean(Vid_Games, na.rm = TRUE))
Modell4 <- lm(Aggression ~ Vid_Games +
Anti_Soz_hoch +
Vid_Games * Anti_Soz_hoch,
data = DATEN_z)
olsrr::ols_vif_tol(Modell4)
## Variables Tolerance VIF
## 1 Vid_Games 0.8318770 1.202101
## 2 Anti_Soz_hoch 0.9993801 1.000620
## 3 Vid_Games:Anti_Soz_hoch 0.8314800 1.202675
sjPlot::tab_model(Modell4,
show.ci = FALSE,
show.std = TRUE, # zeige die standardisierten Koeffizienten
show.est = TRUE, # zeige die unstandardisierten estimates
show.r2 = TRUE, # zeige R^2
show.fstat = TRUE
)| Agression | ||||
| Predictors | Estimates | std. Beta | p | std. p |
| (Intercept) | 38.17 | -0.00 | <0.001 | 0.968 |
| Video Games(Hours per week) |
0.10 | 0.11 | 0.238 | 0.008 |
| Anti Soz hoch | 13.52 | 0.37 | <0.001 | <0.001 |
| Vid_Games:Anti_Soz_hoch | 0.77 | 0.15 | <0.001 | <0.001 |
| Observations | 442 | |||
| R2 / R2 adjusted | 0.183 / 0.177 | |||
6.7 Kategoriale UV
R-Chunk
Modell5 <- lm(Aggression ~ Vid_Games + Anti_Soz_hoch + Anti_Soz_mittel +
Vid_Games * Anti_Soz_hoch + Vid_Games * Anti_Soz_mittel,
data = DATEN_z)
olsrr::ols_vif_tol(Modell5)
## Variables Tolerance VIF
## 1 Vid_Games 0.2266636 4.411824
## 2 Anti_Soz_hoch 0.7390622 1.353066
## 3 Anti_Soz_mittel 0.7373241 1.356256
## 4 Vid_Games:Anti_Soz_hoch 0.5739909 1.742188
## 5 Vid_Games:Anti_Soz_mittel 0.2730809 3.661919
sjPlot::tab_model(Modell5,
show.std = TRUE, # zeige die standardisierten Koeffizienten
show.est = TRUE, # zeige die unstandardisierten estimates
show.ci = FALSE,
show.r2 = TRUE, # zeige R^2
show.fstat = TRUE,
string.est = "b",
string.std = "std. b"
)| Agression | ||||
| Predictors | b | std. b | p | std. p |
| (Intercept) | 30.79 | -0.00 | <0.001 | 0.958 |
| Video Games(Hours per week) |
0.05 | 0.10 | 0.766 | 0.015 |
| Anti Soz hoch | 20.90 | 0.57 | <0.001 | <0.001 |
| Anti Soz mittel | 10.29 | 0.40 | <0.001 | <0.001 |
| Vid_Games:Anti_Soz_hoch | 0.82 | 0.16 | <0.001 | <0.001 |
| Vid_Games:Anti_Soz_mittel | 0.03 | 0.01 | 0.865 | 0.865 |
| Observations | 442 | |||
| R2 / R2 adjusted | 0.299 / 0.291 | |||
7 Interaktion zweier metrischer Variablen

Interaktion zweier metrischer Variablen (in Worten)
R-Chunk
# verändere alle numerischen Variablen, indem sie z-transformiert werden (scale)
DATEN_z <- DATEN |>
mutate(across(everything(), ~.x - mean(.x, na.rm = TRUE)))
Modell5 <- lm(Aggression ~ Vid_Games * CaUnTs,
data = DATEN_z)
olsrr::ols_vif_tol(Modell5)
## Variables Tolerance VIF
## 1 Vid_Games 0.9930553 1.006993
## 2 CaUnTs 0.9974262 1.002580
## 3 Vid_Games:CaUnTs 0.9950094 1.005016
sjPlot::tab_model(Modell5,
show.std = TRUE, # zeige die standardisierten Koeffizienten
show.est = TRUE, # zeige die unstandardisierten estimates
show.ci = FALSE,
show.r2 = TRUE, # zeige R^2
show.fstat = TRUE,
string.est = "b",
string.std = "std. b"
)| Agression | |||
| Predictors | b | std. b | p |
| (Intercept) | -0.09 | -0.01 | 0.854 |
| Video Games(Hours per week) |
0.17 | 0.09 | 0.014 |
| Callous Unemotional Traits |
0.76 | 0.58 | <0.001 |
| Vid_Games:CaUnTs | 0.03 | 0.14 | <0.001 |
| Observations | 442 | ||
| R2 / R2 adjusted | 0.377 / 0.373 | ||
Interaktionen zwischen metrischen Variablen zeigen an, inwiefern der Anstieg der einen UV mit dem grösser werden der anderen UV steigt. Also:
- Die Nutzung von Videogames hat einen signifikanten, aber sehr geringen Einfluss auf Aggression.
- Antisoziale Persönlichkeitsmerkmale korrelieren stark mit Aggression
- Je höher die antisozialen Persönlichkeitsmerkmale, desto stärker wird der Zusammenhang zwischen der Nutzung von Video-Games und Aggression
- und: Je mehr Videospiele jemand spielt, desto grösser wird der Zusammenhang zwischen Antisozialen Merkmalen und Aggression.
LEF 6
Essayfragen 6
E6.1 Was ist eine Slope-Dummy-Variable?
E6.2 Wenn Sie die Hypothese haben, dass der Nachrichtenfaktor «Personalsierung» stärker wirkt, je älter die Befragten sind, wie würden Sie das Regressionsmodell formulieren (Gleichung)? Sie können auch die Modellschreibweise von R verwenden, also lm().
Formel-Lösung E6.2
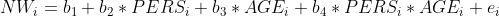
E6.3 Warum ist beim Rechnen mit Slope-Dummys die Multikollinearität ein besonderes Problem? Wie können Sie das bei Slope-Dummys (und nur hier) lösen?
E6.4 Zeichnen Sie ein typisches Beispiel für einen Zusammenhang, den man mit einer Slope-Dummy modellieren würde. (Tipp: Es braucht ein Koordinatensystem und dann zeichnen Sie da Punkte mit unterschiedlichen Farben und Regressionsgeraden rein.)
Lösung E6.4

E6.5 (war fast wie 6.3 und wurde mit ihr zusammengelegt)
E6.6 Wie bilden Sie in R eine Slope-Dummy (Interaktion zwischen einer Dummy und einer Metrischen)
MC-Fragen 6
MC 6.1.
MC 6.2.
MC 6.3.
MC 6.4.
MC 6.5.
Insgesamt von Punkten, was % und etwa einer entspricht.